McGill University Library has recently attained an important milestone: Over the course of the past 6 months, over 13,500 digitized books have been uploaded to the Internet Archive (IA). With over 8,000,000 fully accessible eBooks and texts, the Internet Archive has become the foremost resource for accessing digitized material. IA’s close collaboration with over 1,100 Library institutions enables the collection to be available to a vast network of researchers. Furthermore, the Internet Archive allows our collection to be harvested into HathiTrust, a digital partnership between major research institutions and libraries.
The McGill University Library Internet Archive collection consists of digitized materials from different branches of the McGill Library, ranging from Rare Books and Special collections to notable collections such as Chapbooks and the McGill Student Publications. Our digital collection is growing steadily every week. Because most of the digitized items originated as patron digitization requests, the focus of our online collection is curated around user centric needs. Our collection can be searched and browsed using a variety of topics and categories. Below is a screenshot of our Internet Archive Library home page.
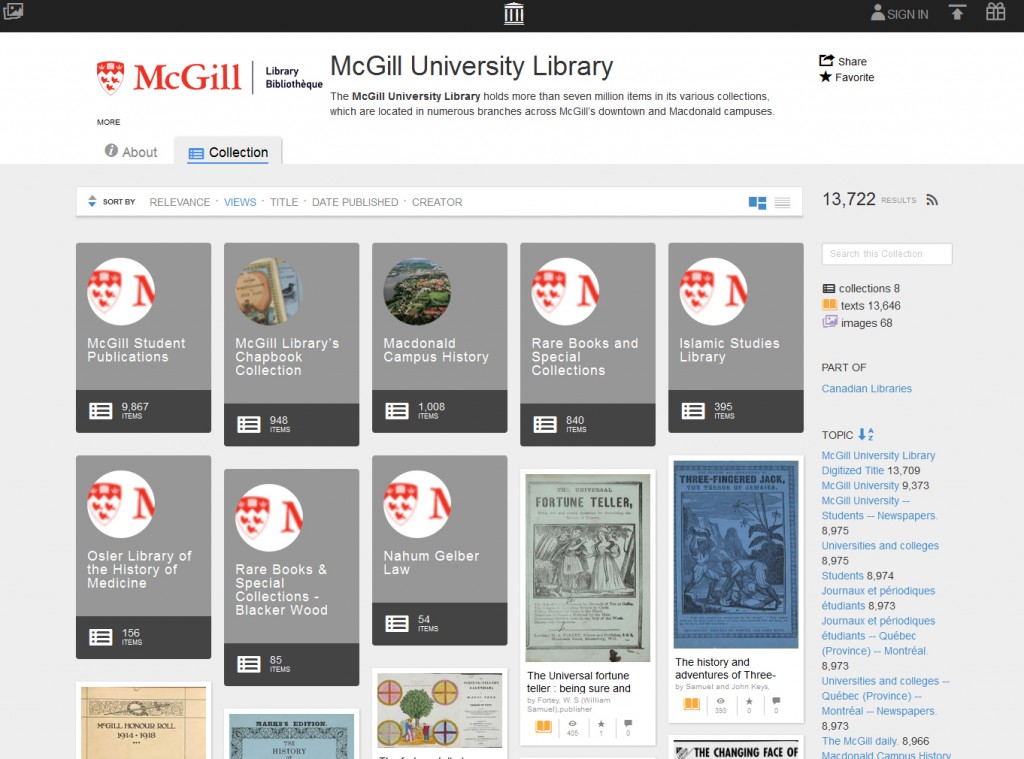
The McGill University Library Internet Archive collection
Books uploaded to the Internet Archive are full-text searchable and can be read online with the Internet Archive’s built-in book reader or downloaded as a PDF. IA also provides mobile device-friendly formats including EPUB and Kindle. Below is an example of a book as viewed from the built-in Internet Archive book reader.
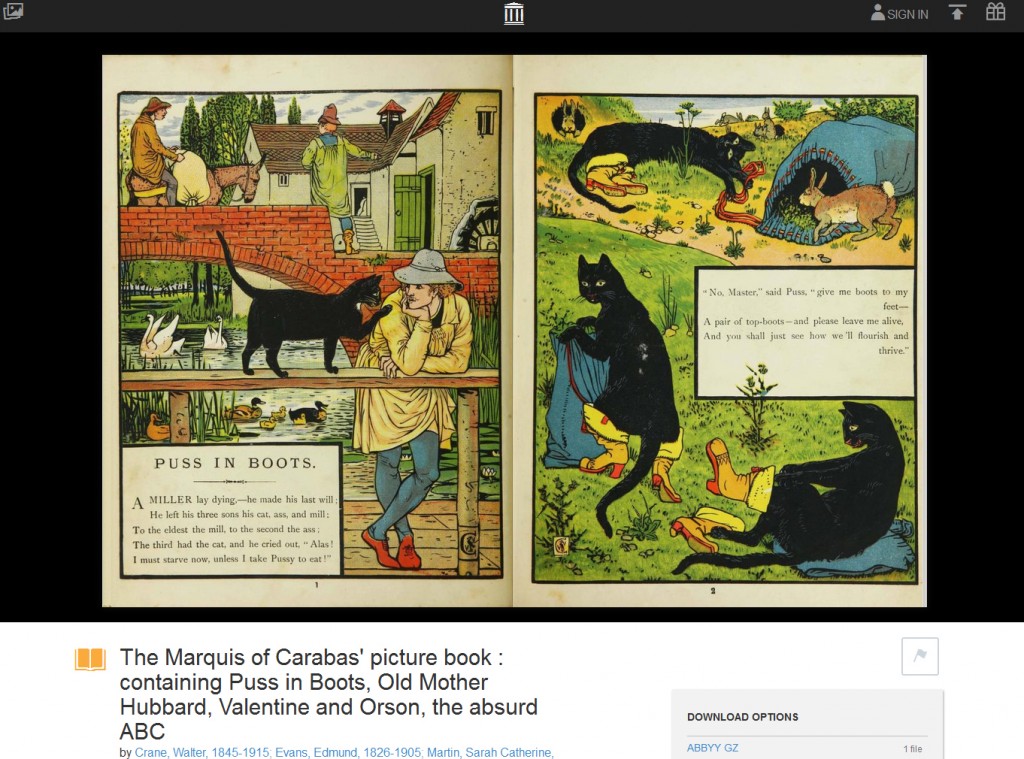
Example of a book as viewed from the built-in Internet Archive book reader. https://archive.org/details/McGillLibrary-104381-365
This initiative could not have been done without the help and support of Sarah Severson, Megan Chellew, Dan Romano and Elizabeth Thomson. A special thanks to Elizabeth who worked diligently to create the necessary tools to batch load digitized material and records into IA and HathiTrust.
You can find newly digitized McGill materials by clicking on this RSS feed link or visiting the McGill University Library Internet Archive page.