Internet archive has started to extract images with no known copyright restrictions from their millions of scanned books and post them to Flickr.
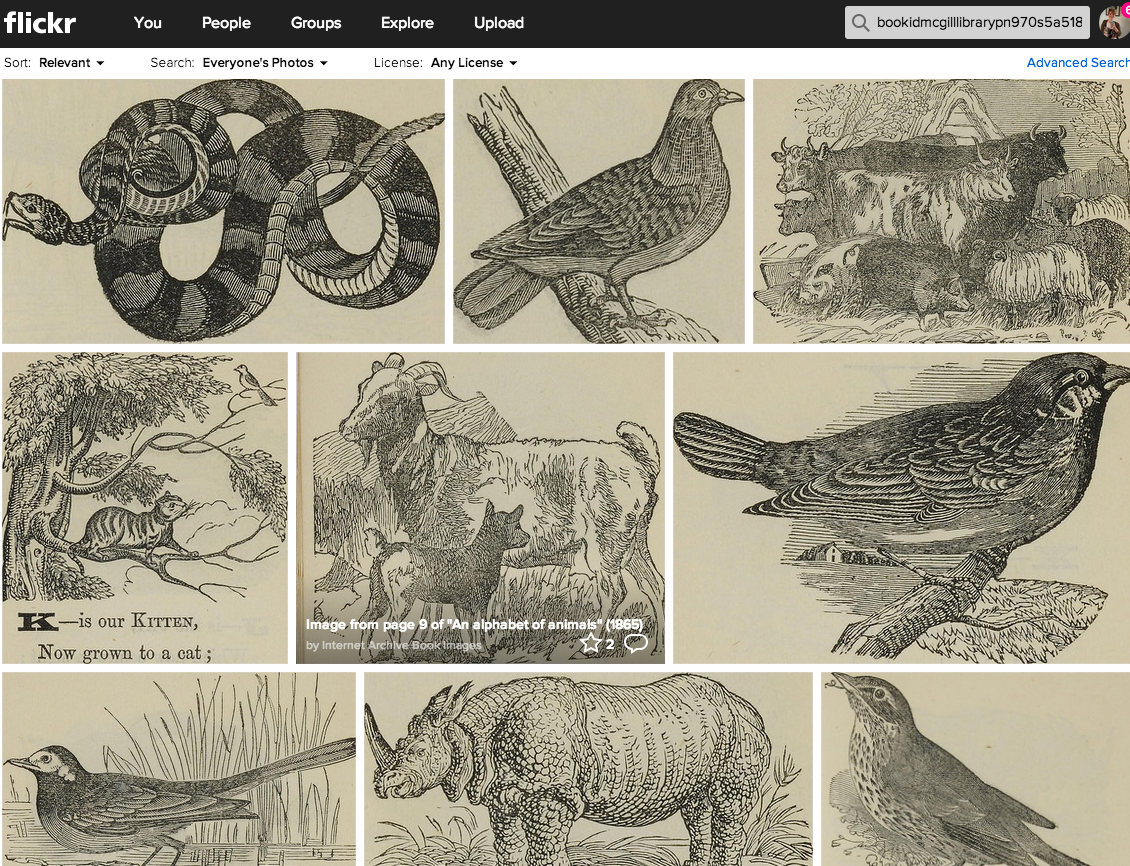
All of the images from “An alphabet of animals” (1865) at https://www.flickr.com/photos/internetarchivebookimages/tags/bookidMcGillLibrary-PN970_S5_A5_1865-2023
Notably each image includes a variety of subject tags extracted from the books original metadata with information like the time period, book publisher or the author so you can search through the collection in many ways.
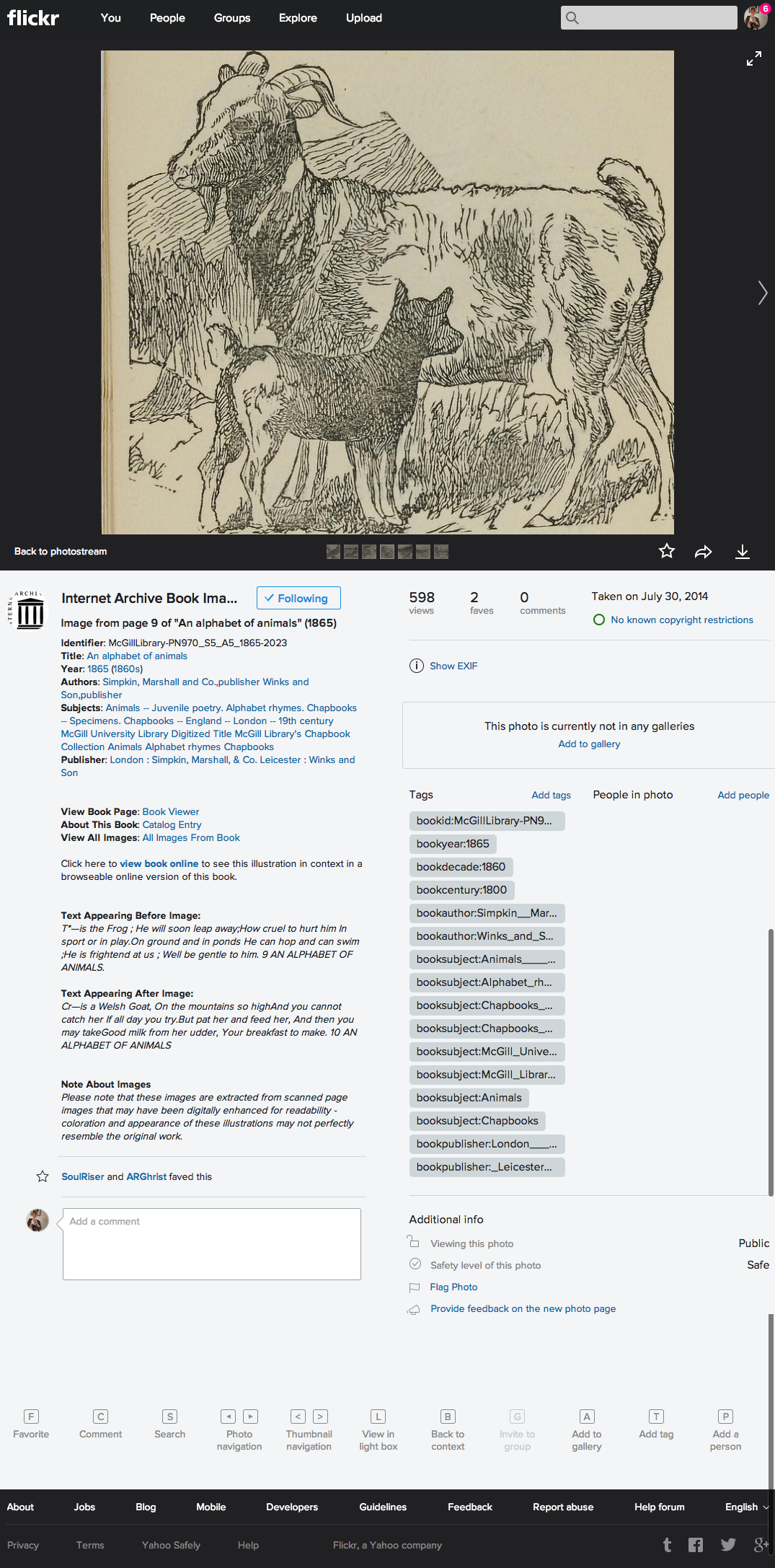
Image from page 9 of “An alphabet of animals” (1865)
Most importantly they have included snippets of the text right before and after the pictures plus a link back to the full book in so you can see the image in context.
An alphabet of animals (1865) full book at the Internet Archive
These are just some examples from our Chapbook collection but there are (as of October 22, 2014) over 2.6 million more images up at their account.
With the algorithm for image detection isn’t always perfect, see
and
it’s a pretty great tool for discovery!