Corpus Coranicum is a European platform supporting scholarship on the Qur’an. Initiated in 2007 by Islamic studies scholar and Qur’anic studies Professor Angelika Neuwirth, the project is today directed by Michael Marx from the Berlin-Brandenburg Academy of Sciences and Humanities. Primarily funded by the German federal government and the federal state of Brandenburg, Corpus Coranicum received external funding from French-German projects Coranica and Paleocoran between 2010 and 2018.
“Corpus Coranicum takes the long overdue step of systematically analysing of the oldest Qur’anic manuscripts as well as documenting the variant readings of the Qur’an within the Islamic literature.”
https://corpuscoranicum.de/en/about/research
The main goal of Corpus Coranicum is to study the historical context in which the Qur’an emerged and developed, and its impacts on the Qur’anic text. To do so, the research team analyses the oldest manuscripts and documents variant readings within the Islamic literature. The first part of the project involved creating a database of digitized manuscripts and building the tools necessary for their analysis (transliteration system, font-type, guidelines on describing and dating manuscripts, etc.). Further developments included a multilingual (Hebrew, Syriac, Ancient South Arabian, Ancient Ethiopic, etc.) database of textual variants present in early Islamic sources. Today, the platform includes four databases:
- Manuscripts including over 30,000 scans of early Qur’anic fragments on parchment, collected from 95 worldwide collections, accompanied by bibliographical, codicological and paleographical data as well as Latin transliterations of the Arabic text
- Variant Readings made of variants found in 8th-9th century scholarly sources like The Arabic grammar of Sībawayh, the Arabic Lexicon of al-Khalīl b. Aḥmad, exegetic texts, grammatical-philological commentaries, Ibn Ḫālawayh’s compendium of variant readings and the Canon of the seven readings compiled by Ibn Mujāhid
- The World of the Qur’an comprising texts produced at the same time that the Qur’an in Arabic, Ancient Ethiopian (Ge’ez), Ancient South Arabian (Sabaic), Aramaic, Syriac, Greek, Latin, Hebrew, Middle Persian, Coptic, etc.
- Commentary consisting of surahs classified based on their historical chronology and thematical development.



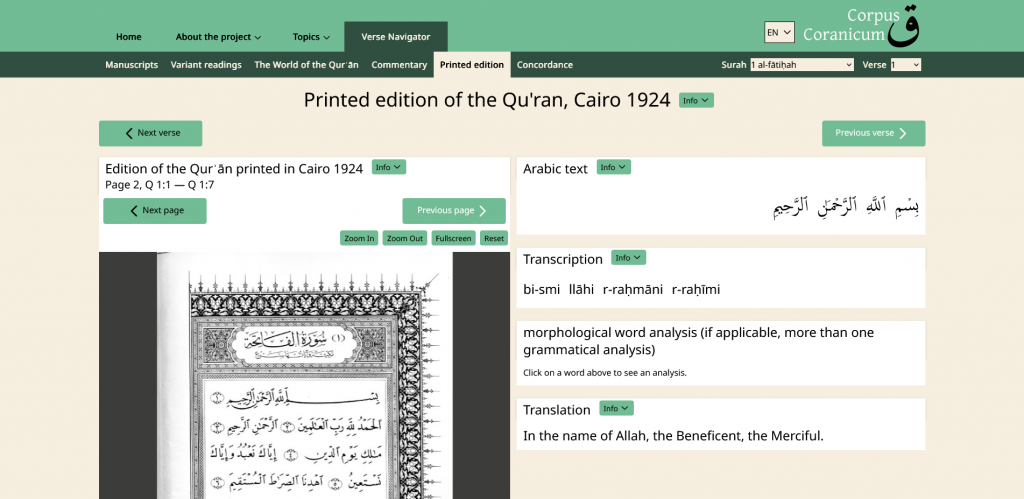
In complement, Corpus Coranicum makes available a 1924 printed edition (Cairo, Egypt) of the Qur’an and Rafael Talmon Qur’an Concordance by word. Rafael Talmon (1948-2004), a Professor of Arabic Studies at the Department of Arabic Language and Literature at the University of Haifa, was a pioneer in the study of the Qur’anic text.

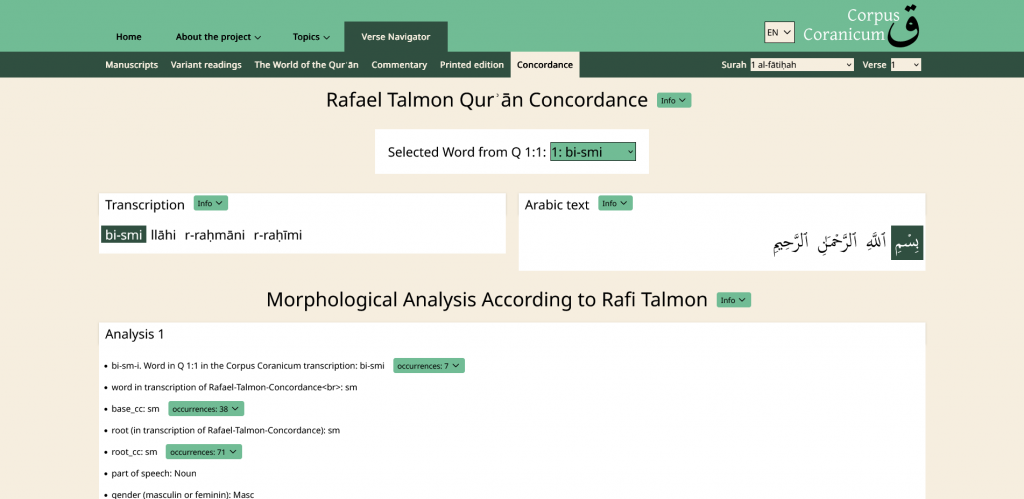
It is possible to navigate verses and access the Arabic text, its transliteration, and translation within the Print edition.
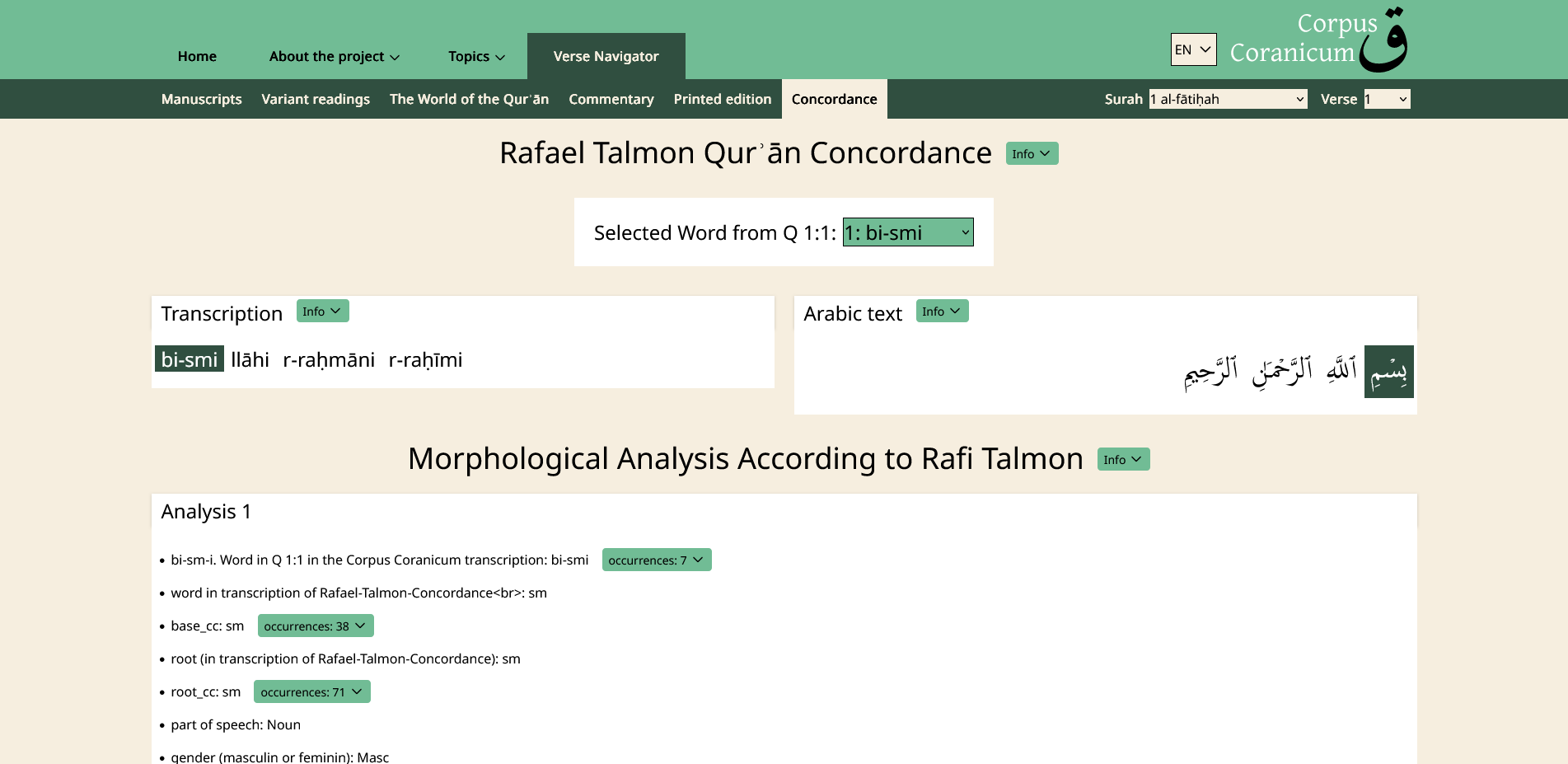
The Concordance provides a systematic morphological analysis (by Rafael Talmon):
Since 2007, Corpus Coranicum has been organizing annual workshops on a variety of topics. To cite only a few:
- Scriptorium Workshop: Qur’anic manuscripts past and present: cataloguing and digital tools, September 18, 2023
- Corpus Coranicum-Vorselung 2022: The Qur’an Palimpsest from Sinai – Interpretations, models and evaluations of Manuscript Cambridge, December 2022
- Corpus Coranicum-Vorselung 2021: Echoes of Jacob of Serugh in the Qur’an and Late Antique reading culture (Philip Michael Forness), December 2021
- Corpus Coranicum-Vorselung 2019: Before the Qur’an: Arabic’s history across Greek, South Semitic, and Aramaic writing traditions, December 2019
- Corpus Coranicum-Vorselung 2018: The Origins and modifications of the Blue Qur’an, December 2018
- Corpus Coranicum-Vorselung 2017: Oman’s new electronic Qur’an solving discrepancies between historical text, rules of calligraphy and Azhar orthography, September 2017.
In addition, between 2016 and 2023, Corpus Coranicum held 39 ‘Collegium Coranicum‘ (i.e. talks) by international scholars on a wide-range of topics related to the study of the Qur’anic text.
Last, but not least, for those interested in learning more about the project and their research methods, two lists of relevant literature can be found on the main page: one on the catalogue of the Berlin-Brandenburgische Akademie der Wissenschaften Library and one as a public Zotero library.
Corpus Coranicum interface is available in German, English, and French: