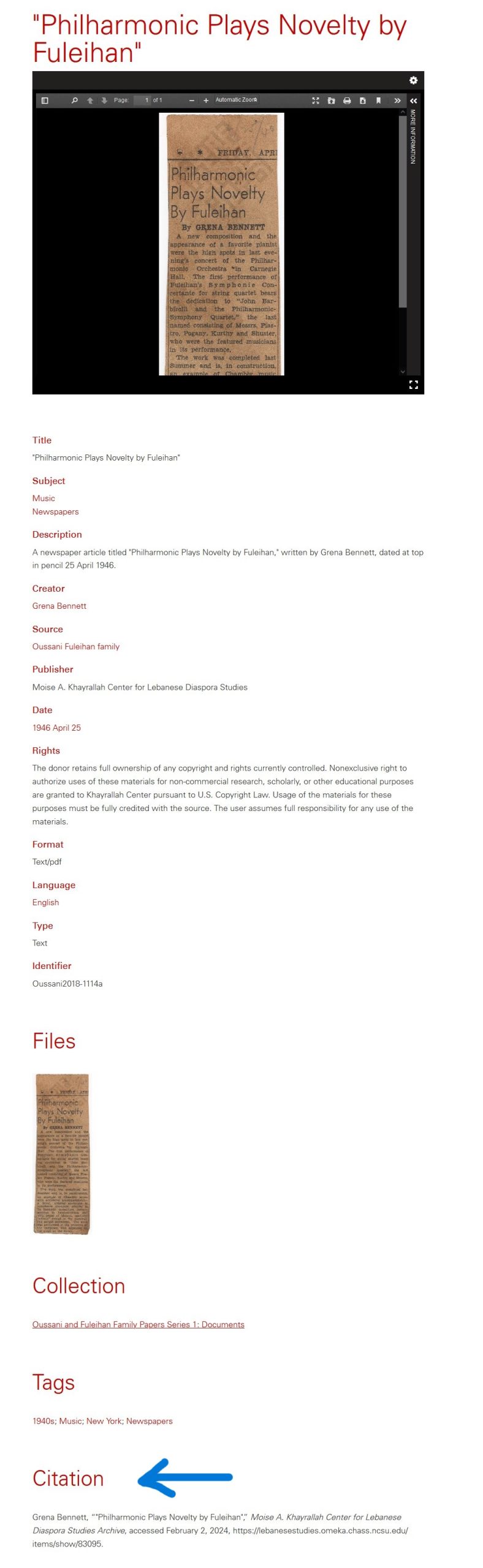
Atassi Foundation was established in 2016 as a non-profit initiative with the mission to safeguard and promote modern and contemporary Syrian art as well as archives from Syria.
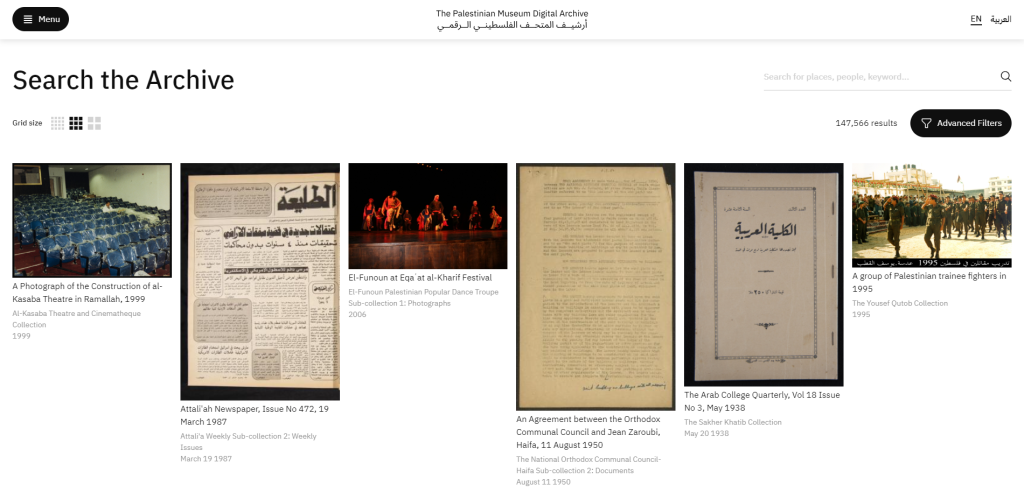
Elias Ayoub, Jasmine Fall, acrylic on canvas, 69 x 139 cm, 2022, presented at New Perspectives Project, @ Foundry from February 27th to April 10th, 2023
This Foundation is the legacy of Atassi Gallery which was a private art gallery founded by two sisters Mouna and Mayla Atassi in 1986 in the attic of their bookstore. The art gallery later expanded its activities thus hosted some exhibitions by renowned Syrian artists (Fateh Moudarres, Abdullah Mourad, and Ahmad Durak-Sibai). Later the gallery moved from Homs to Damascus and started their international and regional collaborations, symposiums, publication…
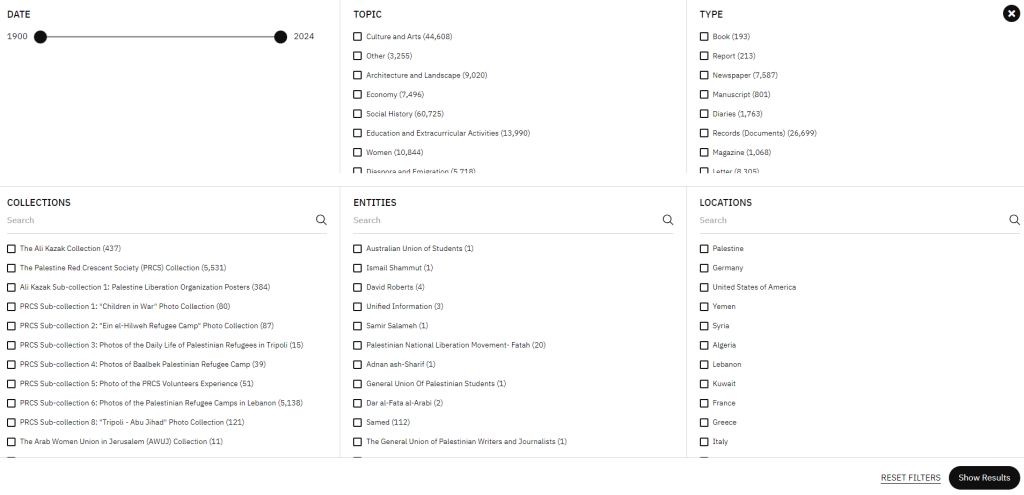
Art work by Mohamad Khayata presented at New Perspectives Project, @ Foundry from February 27th to April 10th, 2023
Atassi Gallery having an important role in Syria’s emerging independent cultural scene, and being hub for intellectuals, writers, filmmakers and artist, transformed into Atassi Foundation in response to challenging times in the recent years with “the belief that art and culture play a necessary and vital role in subduing the ravages of violence, repairing the damages of war and in preserving the history and culture of Syria for generations to come. “
“The voices of artists today rise to counter destruction and violence, to make sense of it and to persevere. Their talents and work are sources of hope, identity and inspiration for future generations.” -Shireen Atassi
https://www.atassifoundation.com/news
Atassi Foundation is aiming to promote Syrian’s cultural heritage as well as critical thinking, research and knowledge promoting to connect the past and future of art production. To achieve this goal, the Atassi Foundation has provided access to a diverse range of materials and information, including various art collection, projects, journal publication (The Journal), podcast (HIWAR) and last but not least an archive collection: Modern Art Syria Archive (MASA).
Atassi Foundation’s art collection consists of early 20th century modern and contemporary Syrian art work and showcases the work of over 70 artists in various forms from paper to photography, sculpture and more.
Artworks are organized by artists’ names, and a description and biography of the artist are provided.
The Projects cover Foundation’s collaborations, Exhibition, research projects and publications. Under each category comprehensive information is provided along with links to the project or research or the collection.
The modern Art Syria Archive is an online archive focusing on modern Syrian art, aiming to draw international attention and interest in Syrian art.
It provides access to three archive collections: The Archives of Atassi Gallery, The Archives of Mahmoud Hammad and The Archives of Leila Nseir. Each consists of various types of archival material including photographs, letters, personal documents, manuscripts and etc, as well as comprehensive information and history about the archive and the artist. Moreover, all the archival materials are accessible as well.
The Archives of Leila Nseir: Leila Nseir at the Faculty of Fine Arts in Cairo, 60s
In summary, the Atassi Foundation is dedicated to preserving Syria’s rich cultural heritage and advancing the future of its artistic landscape.
Art work by Fadi Yazigi: Untitled’ Mixed Media in Box-Front, 26 x 33 x 25 cm
Art work by Fadi Yazigi: “Untitled” 74 x 60 cm. Mixed Media on Paper on Canvas, 2012
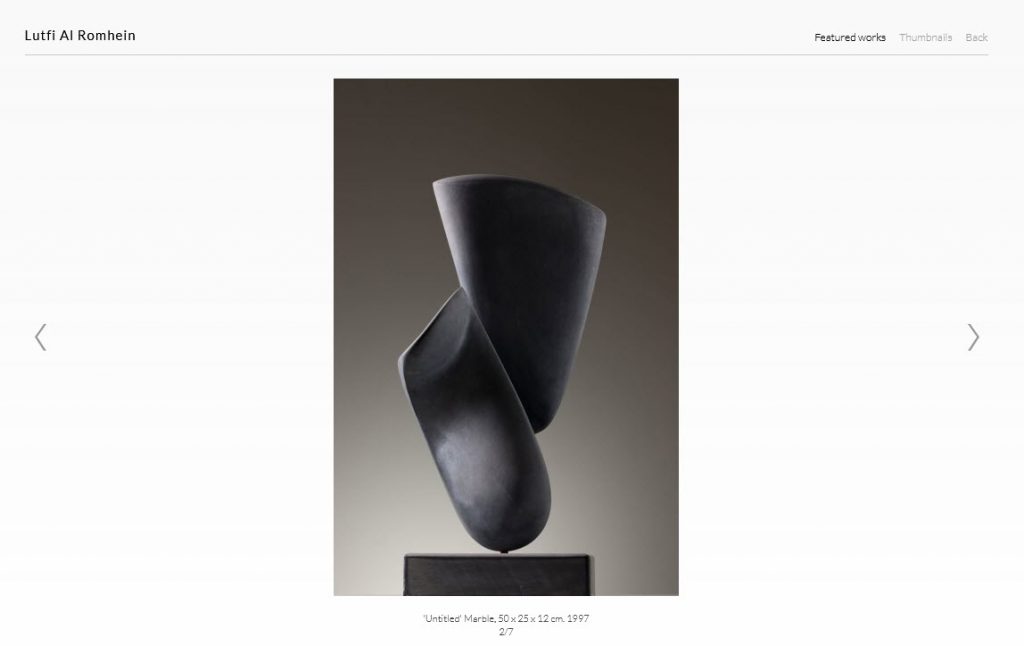
Art work by Lutfi Al Romhein
Art work by Monif Ajaj, at New Perspectives Project, 2021
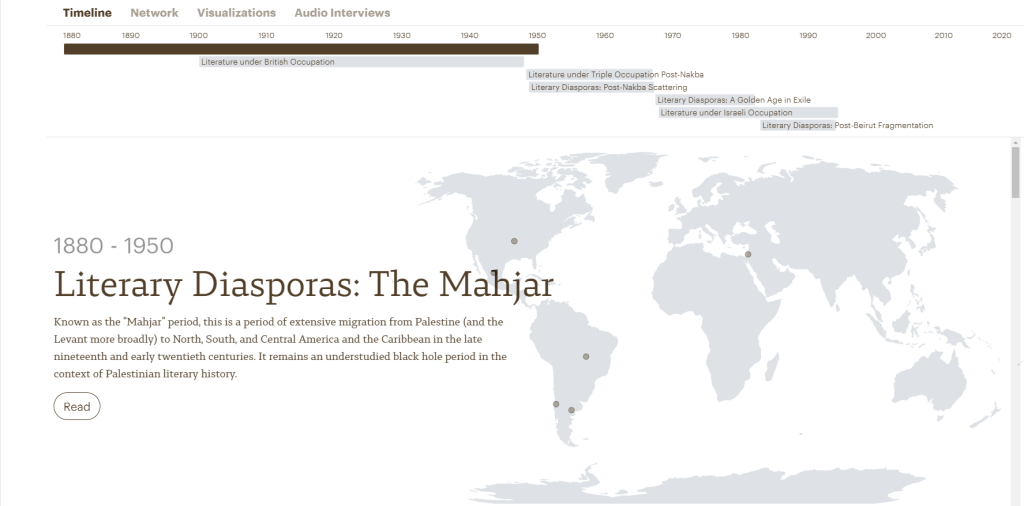
Country of Words aims at uncovering and highlighting the connections between Palestinian literary products originating from different places around the world:
“because of its transnational reality, Palestinian literature makes it possible for us to read together the national and the exilic. It also gives us the opportunity to explore new ways to write nonlinear and nonconventional literary histories of displacement and movement, and to uncover new constellations, networks, trajectories, relationships, and collaborations across multiple literary geographies and periods.”
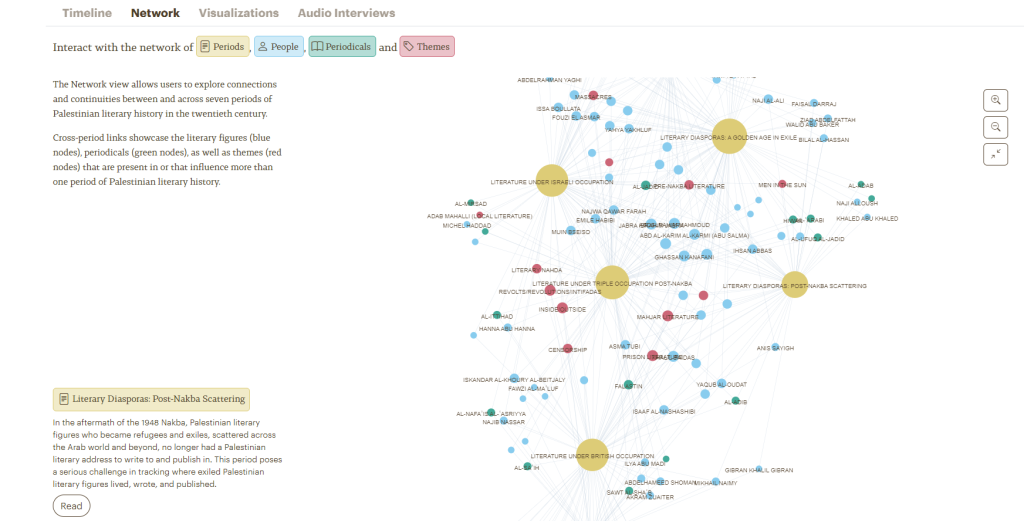
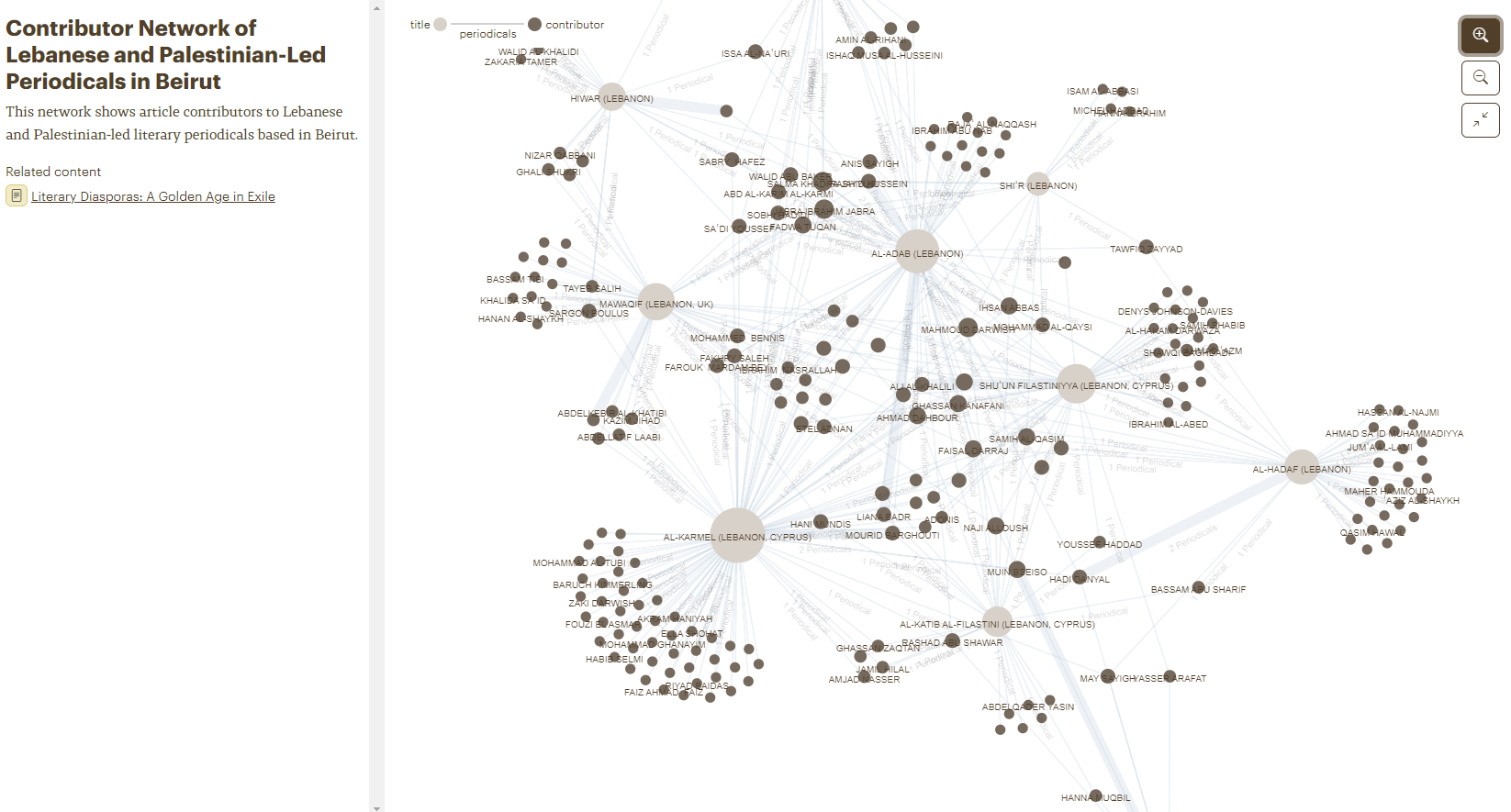
The network mapping allows to visualize and explore the connections between time periods (yellow), authors (blue), periodicals (green) and themes (red). Visitors are invited to click on the nodes to obtain more information about the specific topic.
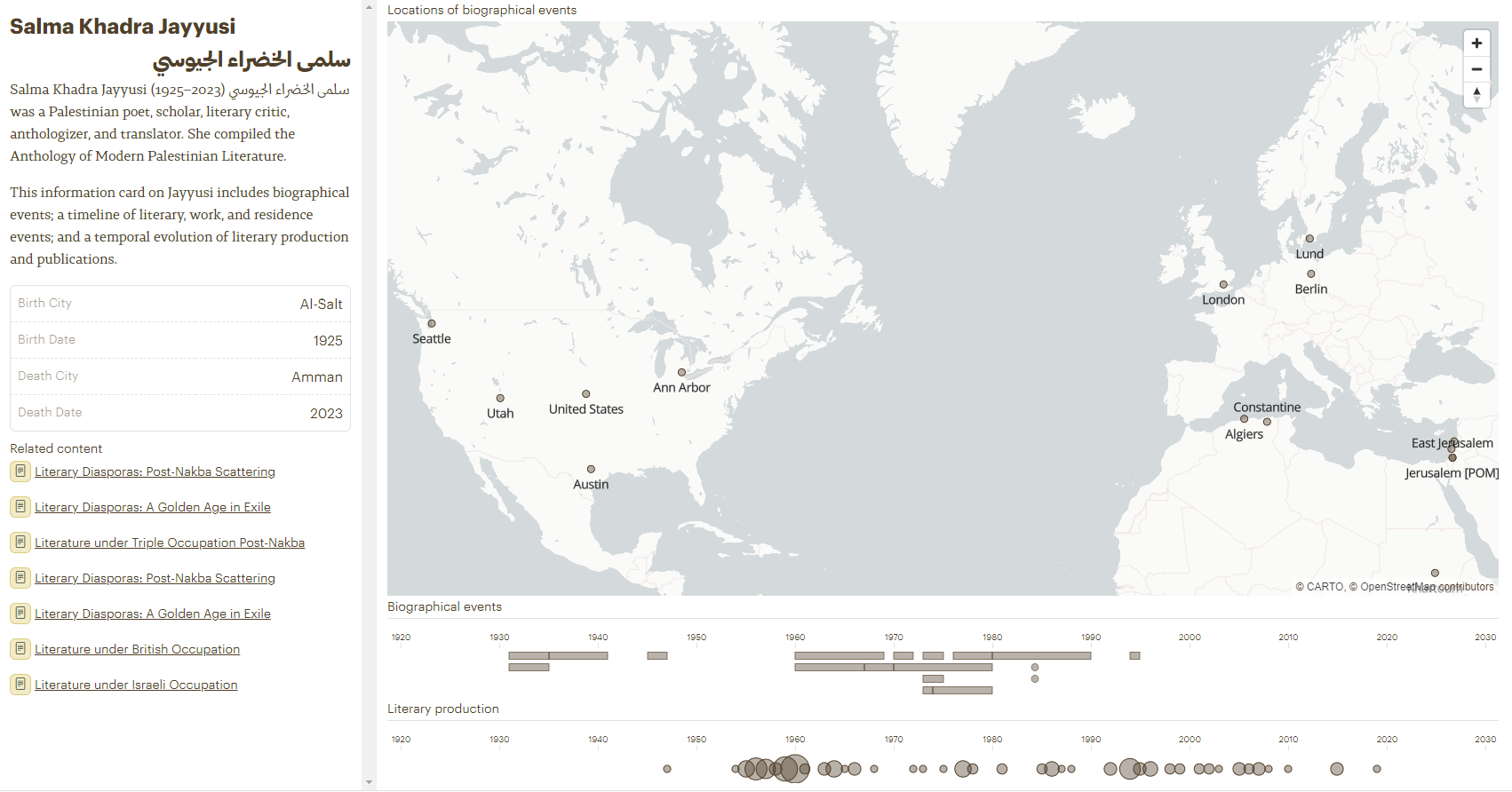
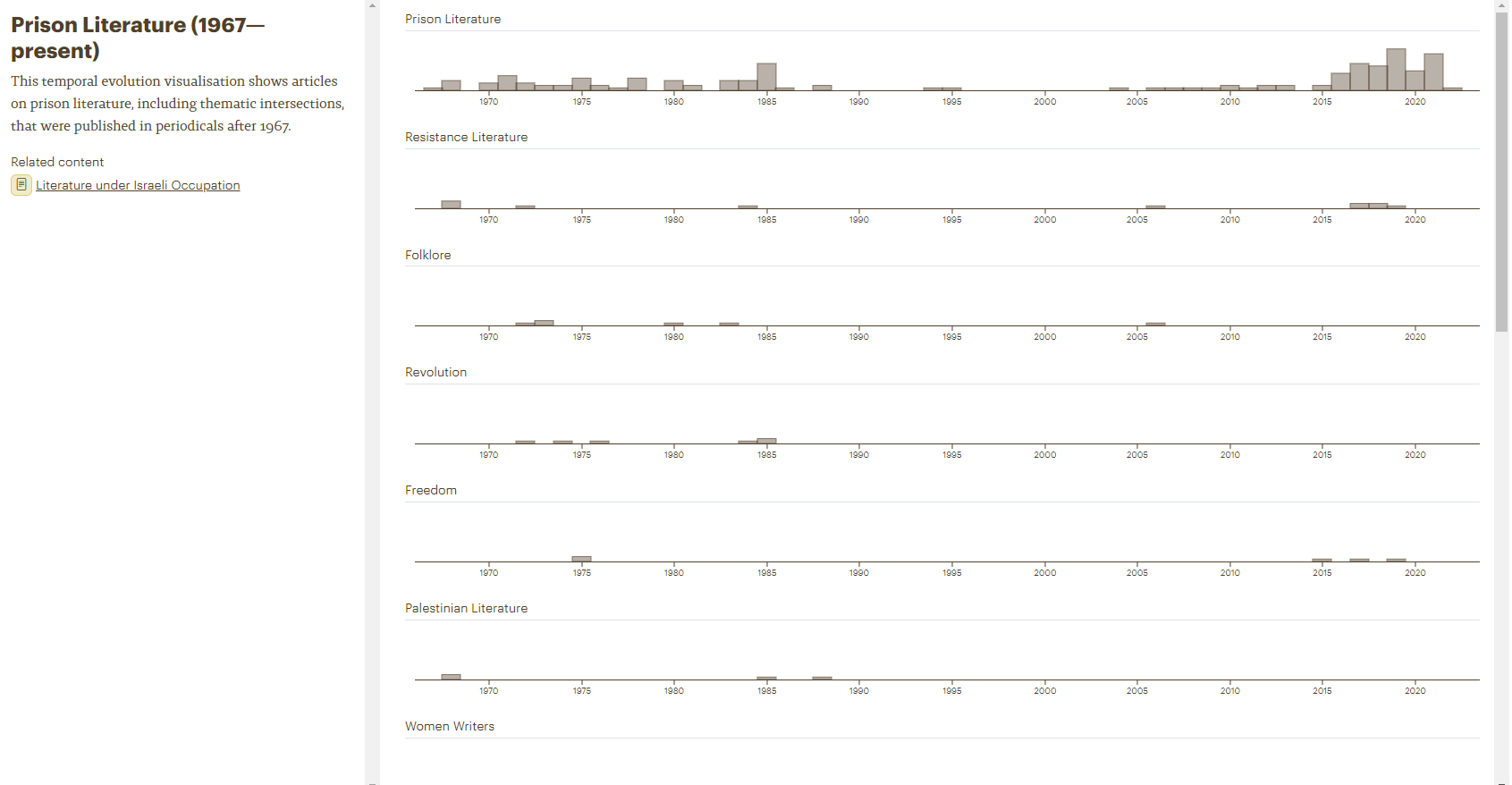
Salma Khadra JayyusiContributor Network of Lebanese and Palestinian-Led Periodicals in BeirutPrison Literature (1967—present)
Visualizations allows to explore the life, migrations and literary production of a writer, contributions to specific periodicals, or the production of a certain type of literature (Prison literature as shown here). Visitors will undoubtedly appreciate the benefits of visualizing information in many different formats.
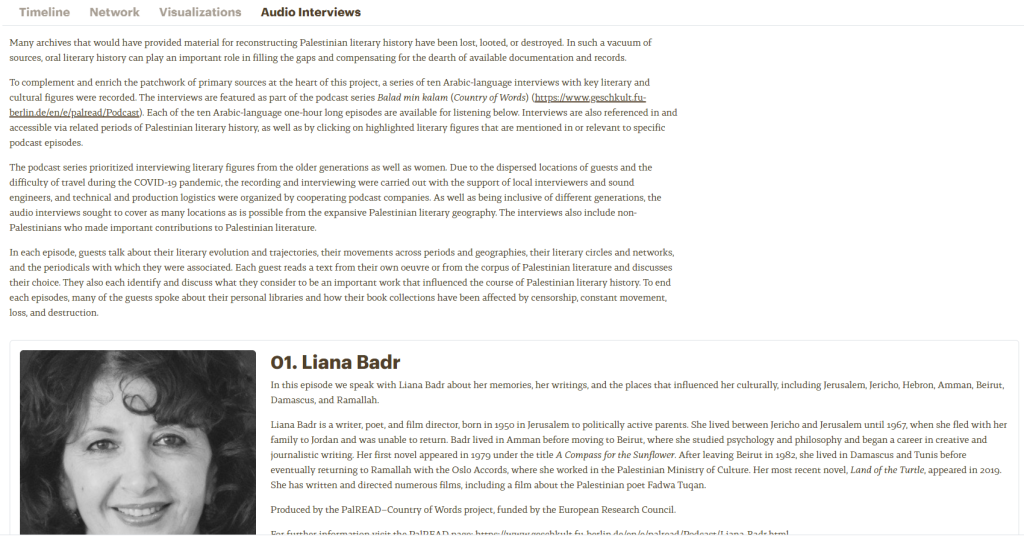
The ten one-hour long interviews of key Palestinian literary figures available on this page are part of a podcast series entitled Balad min kalam (Country of Words). Each episode starts by a discussion of literary evolution, movements across periods and geographies, circles and networks, and periodicals to which they contributed. Then, the guests read a text they have written and explain why they chose it. After that, they are asked to cite a work they think influenced the course of Palestinian literary history. Last, “many of the guests spoke about their personal libraries and how their book collections have been affected by censorship, constant movement, loss, and destruction. Interviews are also indexed and accessible by time period.”
To conclude, we want to note that Country of Words: A Transnational Atlas for Palestinian Literature has been described in very positive terms by many experts in the field. Among them, Professor Michelle Hartman (McGill University) wrote: “With its user-friendly interface, well-suited and attractive visualizations, intelligent analysis, and fascinating author interviews, Country of Words is an invaluable resource that documents and engages the diversity of Palestinian literary production over time, expanding access to it in an inviting digital format.”
The KCLDS Archive serves as the repository for the Khayrallah Center, established in 2010 by Dr. Moise A. Khayrallah. Initially established to research and conserve history of Lebanese in U.S, the center evolved into a larger project and extended beyond the United States, eventually becoming the Moise A. Khayrallah Center for Lebanese Diaspora Studies. As a result of its growth, the center curated a museum exhibit, produced a documentary, and established an archive (KCLDS).
KCLDS Archive houses historical and cultural resources about Lebanese diaspora in the United States and across the world.
“We preserve the heritage and memories of the Lebanese diaspora community and make it accessible through our digital and physical archives.“
The Archive can be explored through three main categories: Collection Guides, Browse the Collection, or Browse the Item. There are 112 collections available, containing a total of 11,634 items.
When using Browse the Collection menu, you can search either in title order or based on the time the item was added to the collection. Detailed information is provided for each collection, such as: Title, Subject, Biographical/Historical Note, Publisher, Date, Language, etc. but more importantly a full description of the collection and finally access to the collection.
Moreover, searching on the item level gives more search criteria, such as Browse by Tag, Item or Reference, also results can be sorted by Title, Creator, Item Date, etc.
Another valuable feature at the item level is the Citation section. When available it is possible to see if the resource was cited, when where and by who.
.
.
.
.
.
.
.
.
.
.
.
.
.
..
.
.
.
.
.
.
Collection Guides, however, provide access to the collection by title or categories.
Moreover, it is possible to search in Arabic using the Arabic-Language Publication Database menu, which provides access to Arabic- language newspaper and books in the States between 1880s to 1950s.
Early Arab immigrants in North and South America have left a rich legacy and history. Much of their histories have been recorded in millions of pages of Arabic newspapers, books, magazines, and other publications. Yet, this rich record has been largely inaccessible because it was dispersed, stored in disparate archives, and stored in older technologies like microfilm. Now, The Khayrallah Center’s Arabic Newspaper Database makes these records digitally searchable.
KCLDS Archive offers variety of resources for researchers, scholars, and anyone interested in exploring Lebanese diaspora. The archive not only preserves the past but also sheds light on the present and provides access to resources for future. With its diverse collection guides, browsing options, and Arabic-Language Publication Database, the archive invites users to access its wealth of materials, facilitating research, discovery, and understanding of the Lebanese diaspora’s journey, memories, and heritage.
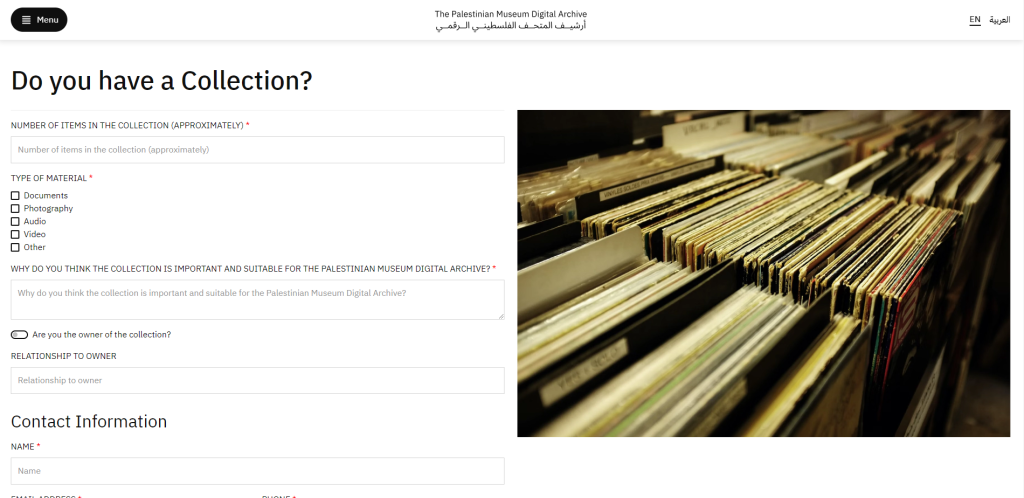
Sponsored by the Arcadia fund, the Palestinian Museum Digital Archive aims at collecting, digitizing and making widely available (in Open Access) endangered archival materials documenting Palestinian life and history. Started in 2018, the project has now reached its third phase involving partnerships inside and outside Palestine as well as a broadening of the geographical scope covered.
At the time of our visit, the archive included over 200,000 documents like “identification papers, official records, letters, diaries, manuscripts, maps, photographs, films, and audio recordings” collected from individuals, families, and institutions. The Palestinian Museum Digital Archive only keeps digital surrogates and return the original documents to their owners after processing.
Visitors can either Search the archive, Browse collections or Explore topics.
The basic search only requires to enter keyword(s) in the search bar at the top-right corner of the page. The advanced search offers a more refined search where you can limit by:
The collection browse allows to identify specific archives of interest before searching them. The number of documents in each collection range from less than a hundred to thousands of documents. The time period covered is clearly stated at the right-top corner of each collection:
The topics exploration offers a different way of navigating the website through subjects assigned to documents. Among the long list of topics (fifteen in total), visitors will find the following:
The number of documents in each category is indicated right beside the topic, and when scrolling over the topic, a series of thumbnails gives a snapshot of items that will be found under this topic. To ease navigation, the list could be sorted alphabetically.
It is important to note that all materials in the Palestinian Museum Digital Archive are “copyrighted either by the museum or by third parties who have granted permission for their materials to be included on this site. Visitors can therefore only use the documents “for personal, educational, non-commercial use, or for fair use as defined in the United States copyright laws.” It is possible to ask for high-resolution images by emailing info@palarchive.org or sending the request via the form available here.
To submit your personal archive, you may fill out the following form:
The website is entirely bilingual English and Arabic.
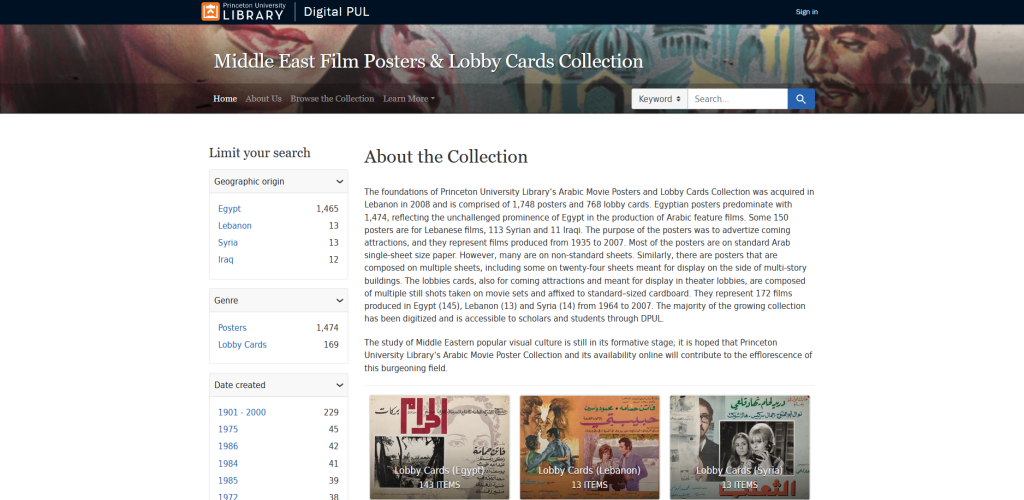
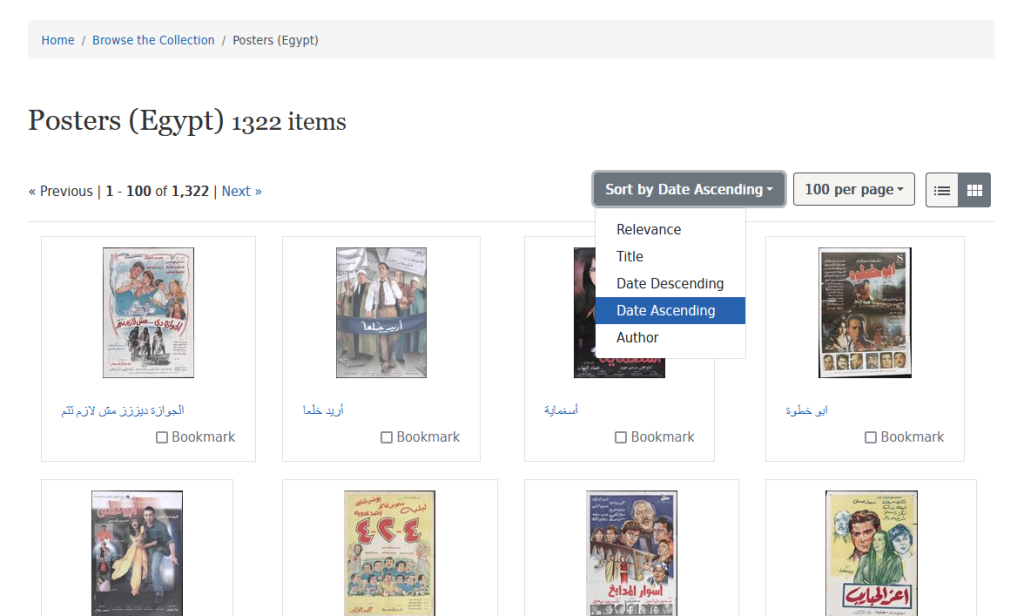
The Middle Eastern Film Posters & Lobby Cards Collection is a digital collection launched by Princeton University Library to make available their Arabic Movie Posters and Lobby Cards collection to worldwide scholars. Acquired in Lebanon in 2008, the collection includes 1,748 posters, and 768 lobby cards produced mostly in Egypt, Lebanon, Syria and Iraq. At the time of our visit, the digital collection included 1,646 items which represents a large proportion of the overall collection, and newly digitized items keep being added to it.
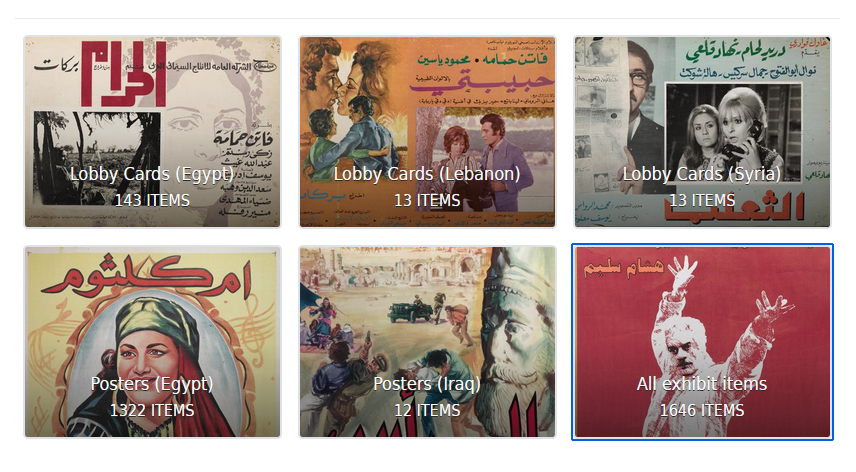
The digital collection can be navigated in two ways. The left-hand side filters allow visitors to limit their search by place of origin, genre or date of creation. The categories accessible via the vignettes below allow to access the materials sorted by both genre and geographical origin:
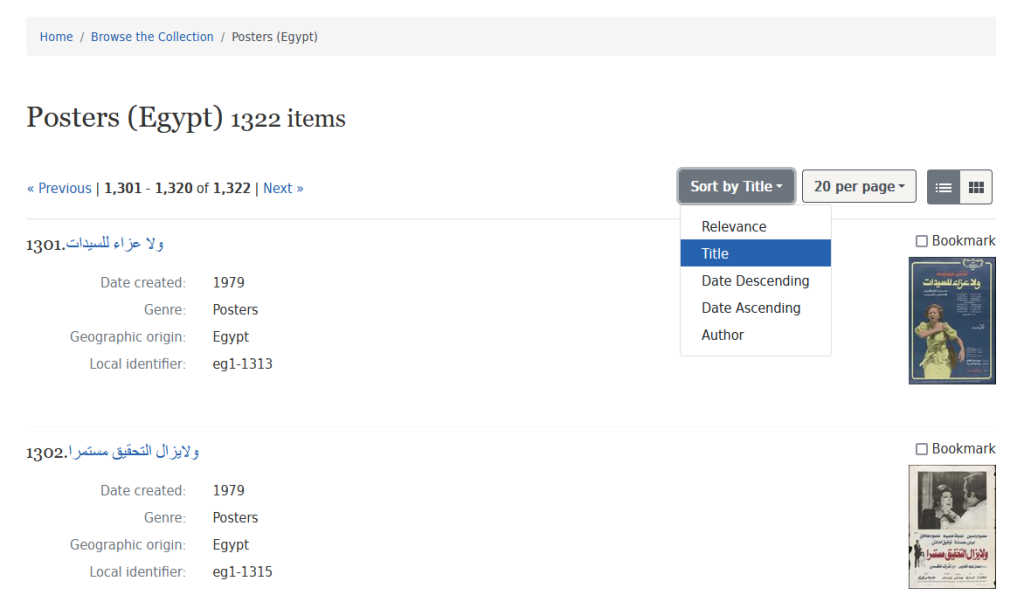
Within each category, results can be displayed either in a list or a table form, and sorted by title, author, and date (ascending/descending).
When opening an item, the page will show the high resolution image and a succinct description at the bottom. For more information about the document, visitors can expand the right-hand side panel. Images can be displayed full-screen, enlarged and reduced, downloaded (as jpeg, tiff or pdf) or shared via a link.
In addition to aiming at identifying and locating archival materials indispensable to scholarship, the project also explored faster and more appropriate ways to describe and catalogue archival collections “from an African perspective”. To do so, they reflected on traditional Western archival practices, and worked towards adapting them and/or creating new practice better suited for archival materials in non-European languages. They worked closely with partners at SCOLMA, a “forum for librarians, archivists and others concerned with African studies materials in libraries and archives in the United Kingdom”.
The rationale behind the project is thoroughly explained in this video posted on the ‘About‘ page:
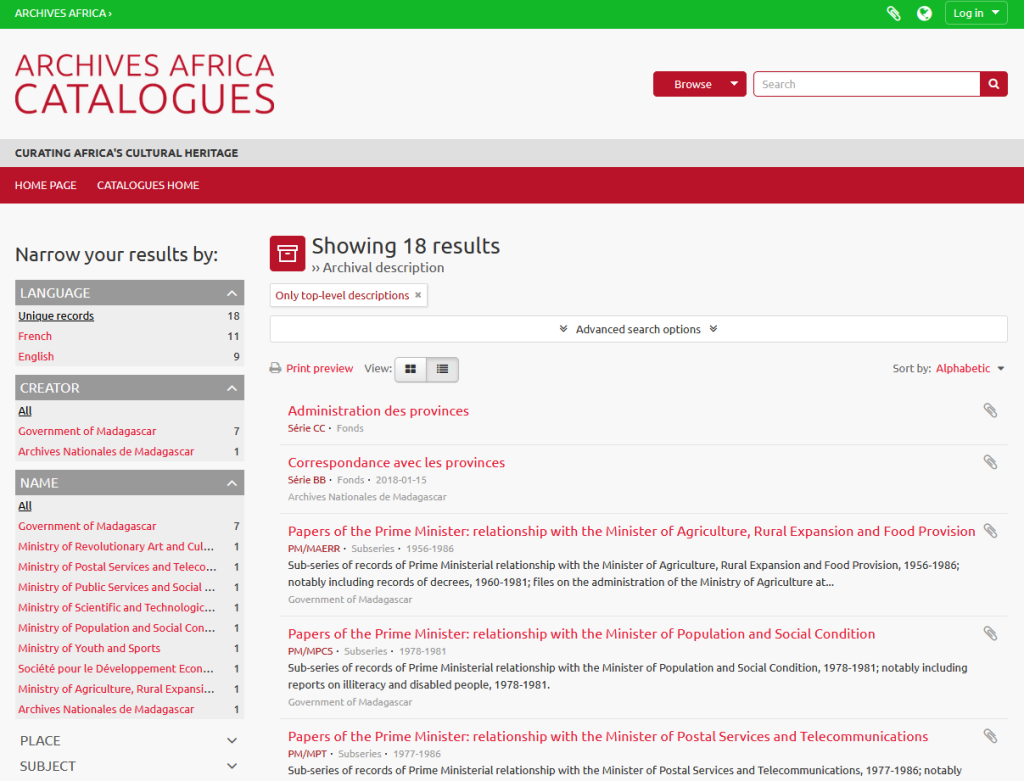
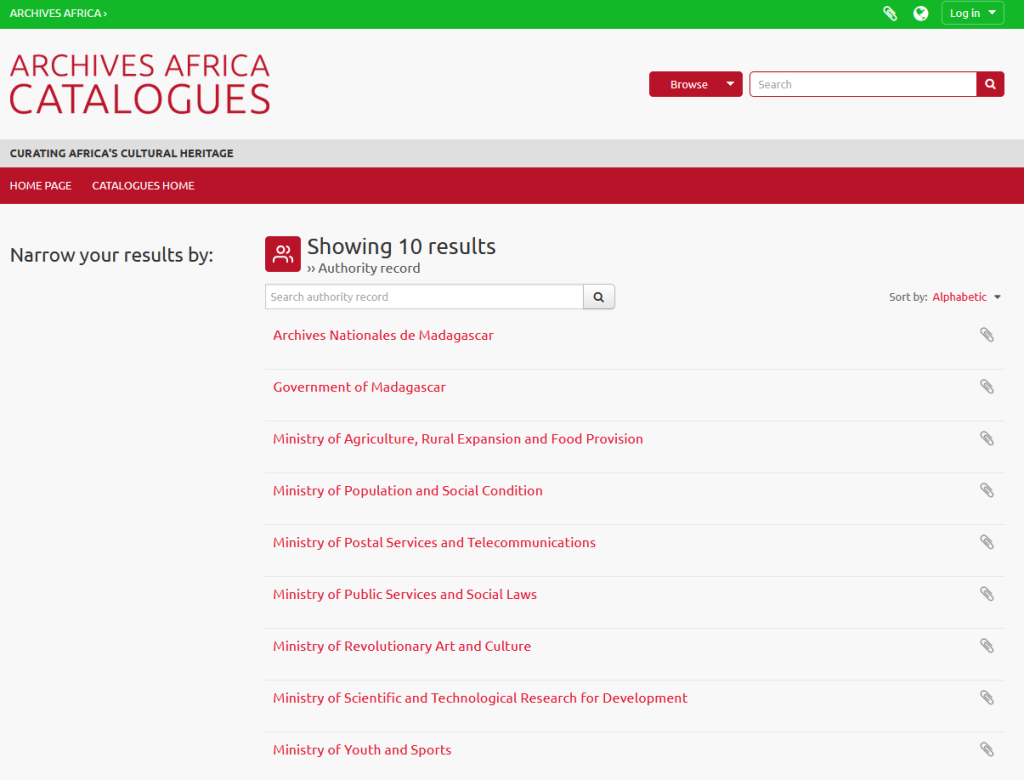
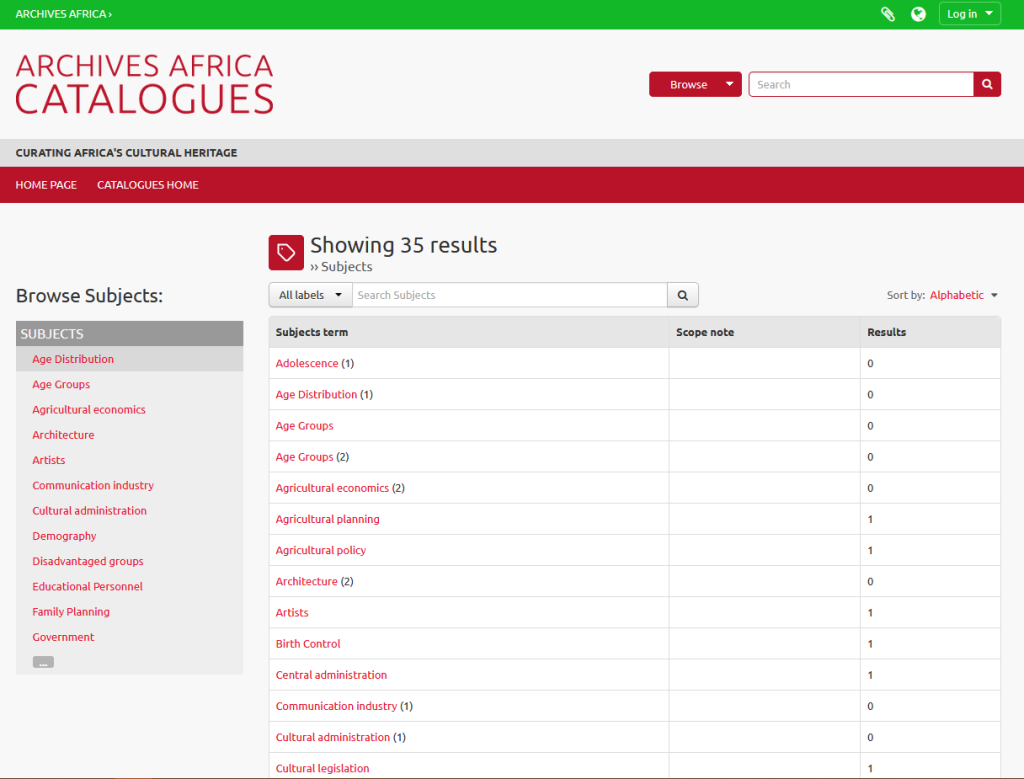
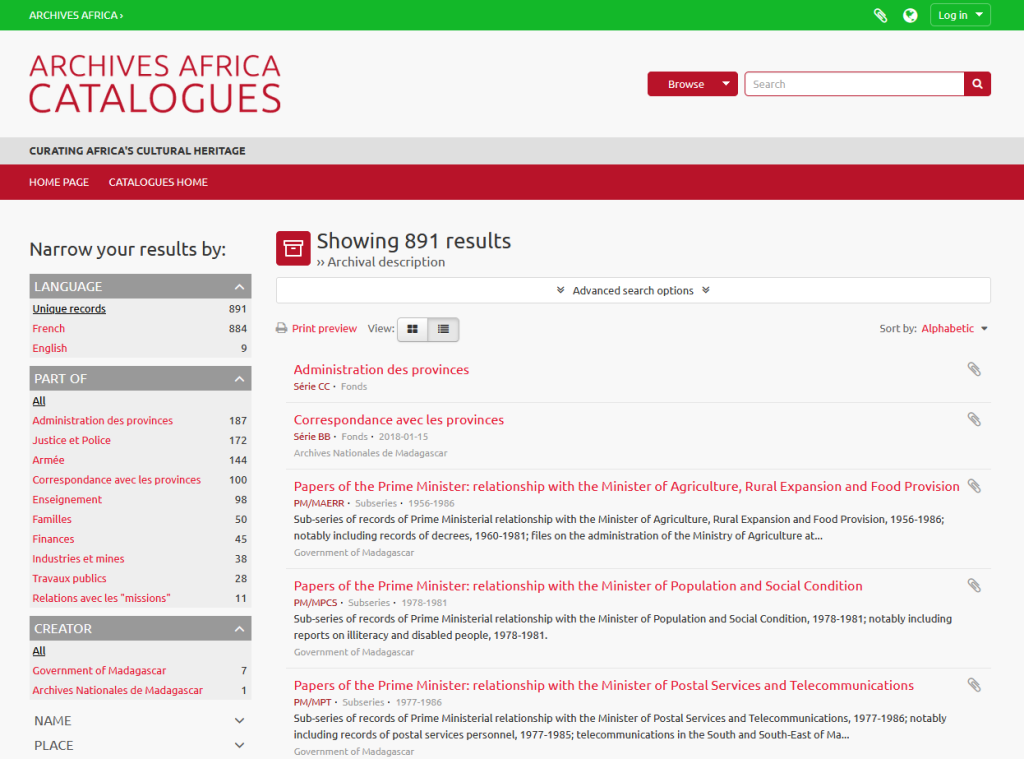
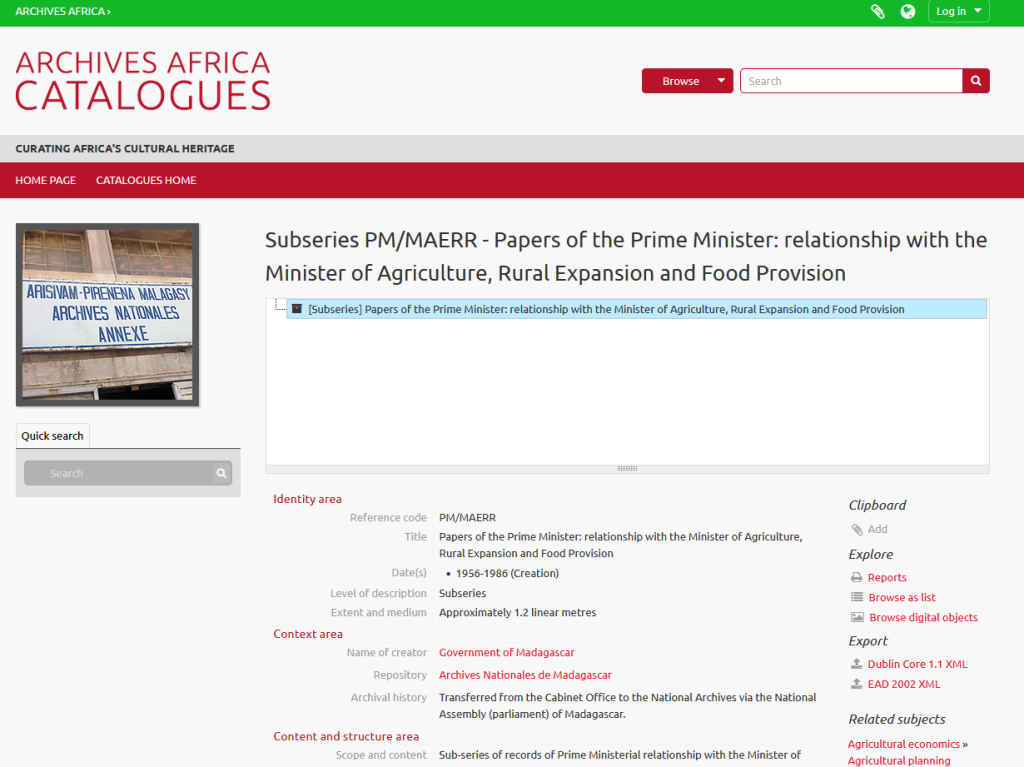
The ‘Archives Africa Catalogues‘ section is the heart of the website as it includes the records of archival collections. Catalogues can be discovered browsing a number of categories:
At the time of our visit, the total number of collections cataloguing records in the database was close to 900, identifying and locating a much larger number of documents in Malagasy, French, and English.
The News section, despite not having been updated since 2018, makes available interesting and insightful information about the project.
Those interested in learning more about African archives further should consult the International African Institute‘s website, in particular the African digital repositories page. Based in the United Kingdom (at the School for African and Oriental Studies, SOAS), the IAI “promotes the scholarly study of Africa’s history, societies and cultures” for which archival sources are essential.
The Walters Art Museum’s collection encompasses art from various cultures extending over seven thousand years. Many of the items in their collection can be explored through their website atworks of art site and Walters Ex Libris.
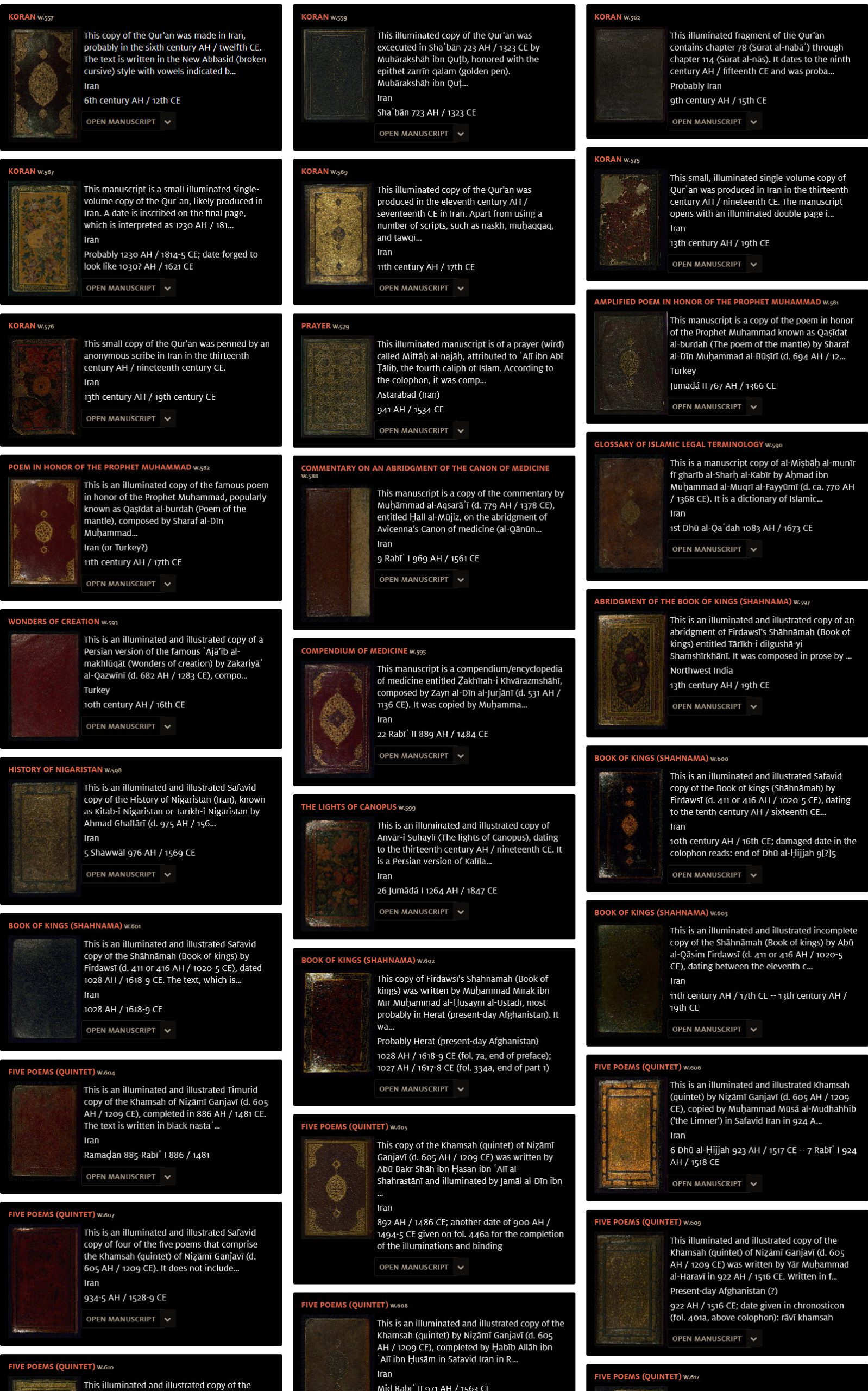
Beyond a wide range of artistic objects, their collection includes manuscripts and artwork on paper, as well as books and remarkable pieces of Islamic art. This includes valuable items like miniature paintings, beautifully illuminated Qurans and etc.
Leaf from Qur’an.
Bowl with Seated Figures Flanking a Tree Islamic (Artist)
Jug with Sphinxes, Griffins, and Heron Islamic (Artist)
Moreover, the Museum is house to” 900 printed manuscripts, 1300 incunabula and 2000 rare books”. Of these, 433 manuscripts and more than 8000 printed papers are digitized and accessible through Walters Ex Libris. These manuscripts cover a variety of periods, including works from the Safavid, Mughal and Ottoman empire.
Moreover, as a museum dedicated to education, storytelling, and fostering community engagement through knowledge and cultural expression, the Walters Art Museum is actively digitizing and making their collection accessible to the public. Some of their digitized exhibitions also serve this purpose. One such exhibition, ‘Poetry and Prayer: Islamic Manuscripts from the Walters Art,’ beautifully showcased a variety of books, manuscripts, and individual art pieces. This collection includes beautifully illuminated manuscripts featuring poetry, prayers, miniature art, the Quran, and more. Each item has been digitized, and an informative description is offered.
While exploring this specific exhibition along with some of their digitized manuscripts, we noticed some similarities or common characteristics between their displayed materials with some of the manuscripts and rare books available at Islamic Studies Library rare book collection. Thus, we decided to highlight some of them as an example.
However, there are many more similar cases to be explored. Some of McGill Islamic Studies Library’s digitized manuscripts and rare books can be found here. The Walters Art Museum manuscripts can be found here.
For example, this Mughal color-wash drawing (portrait of Lal Kunwar) at the Walters Art Museum and this miniature of a princess at McGill Rare book collection, have various elements in common, while created in different time.
……………………………………………………………………………………………………………………………Additionally, these two manuscripts seem to share many characteristics. Both are Persian poetry books, featuring similar calligraphy styles and very comparable ornate illuminations. However, one (“Yusuf and Zulaykha” by Jami) is housed at the Walters Art Museum, and the other one (poetry book by Hafiz ) is at McGill Rare Books. Are these two manuscripts made in the same manuscript workshop but, in the course of history, ended up in two different parts of the world?
Dīvān-i Ḥāfiẓ. 15th century
Yusuf and Zulaykha. 16th century
These two painting share some similarities as well while the miniature of the Mughul Emperor is housed at McGill and the portrait of emperor Jahangir is at The Walters Art Museum.
There are more items at both places that can be compared and explored to find similarities or differences. These two Hafiz poetry books (mentioned above) can be examined from a different perspective. Although they were created around the same time, unlike the previously mentioned example, these two display distinct illustration and calligraphy styles, yet they also share some similarities.
The Walters Art Museum, in line with their commitment to public education and connecting art to people’s lives, publishes the Journal of Walters Art Museum as an open-access resource, providing free access to research about their collection which can be found here and contains valuable information about their collection. While comparing or exploring their collection, this resource can also be used to obtain more background information about their various manuscripts or rare books.
“The Walters Art Museum’s Mission has been to bring art and people together and to create a place where people of every background can be moved by art”
An Exhibition curated jointly curated by the Islamic Studies Library and the Osler Library of the History of Medicine running from September 11th to December 22nd, 2023.
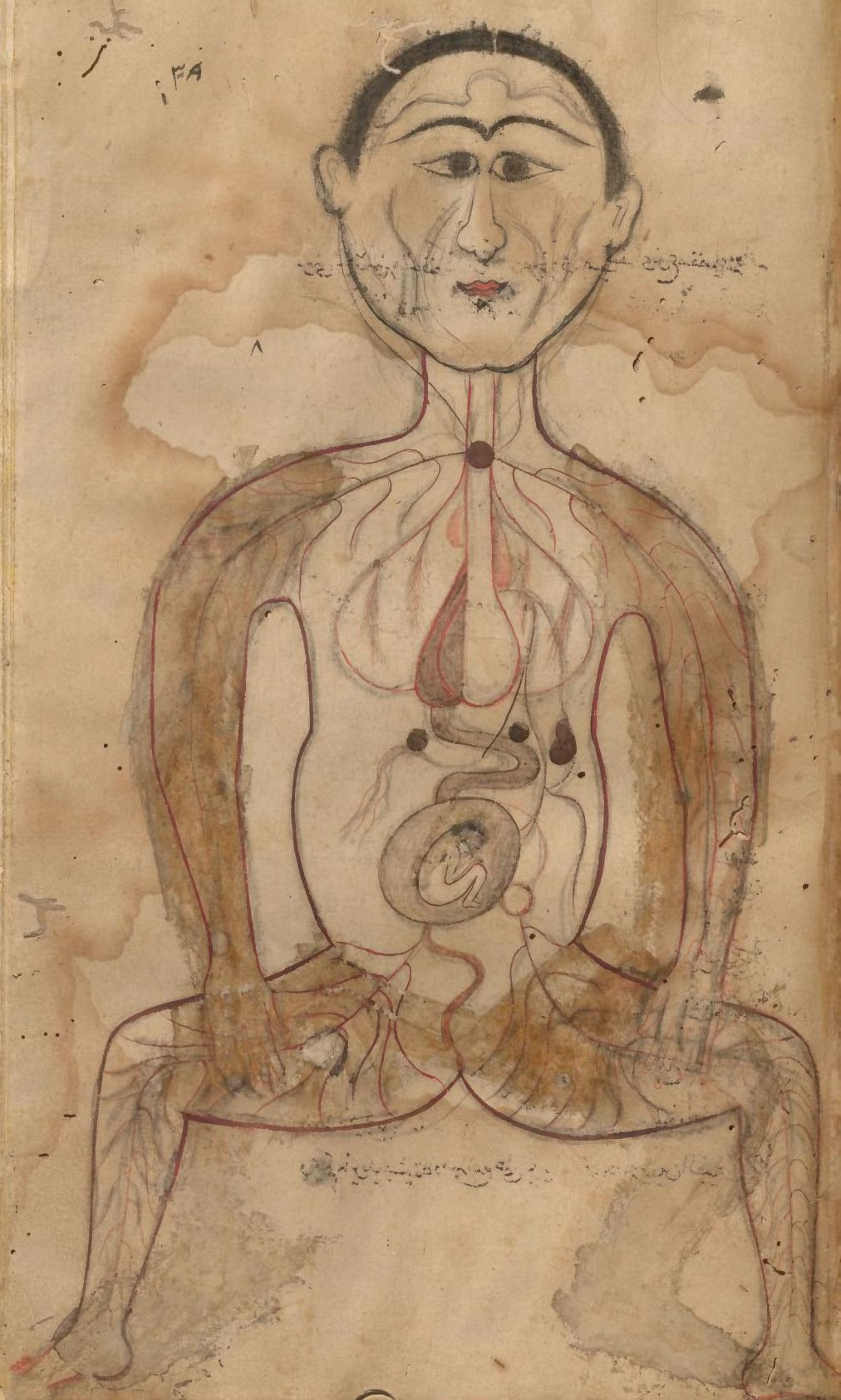
تشریح البدن منصور ابن محمد ابن احمد ابن یوسف فقیه الیاس Tashrīḥ-i badan [Anatomy] by Manṣūr ibn Muḥammad ibn Aḥmad ibn Yūsuf Faqīh Ilyās 16th century. Osler Library of the History of Medicine
The practice of medicine in the region sometimes referred to as the Islamic World[1] predates the revelation of Islam: therapeutic practices before Islam relied heavily on Mesopotamian, Egyptian, Persian, Indian, and Greek medical knowledge. During the early and medieval periods of the Islamic era, physicians in the region achieved advancements and innovations that have had a lasting and significant impact on the evolution of medical practices around the world. This exhibition aims to show how medical knowledge first came to the Islamic World (pre-Islam until the 10th cent. AD/4th cent. AH), then circulated and developed within the region (between the 11th and 16th cent. AD/5th-10th cent. AH), before being exported to Europe (during the 17th and 18th centuries. AD/11th-12th cent. AH).[2] Visitors will learn how the translations of foreign medical texts (from Greek, Sanskrit, Syriac, etc.) into Arabic and Persian eventually led to the need to codify such a large body of knowledge for the purpose of dissemination. Visitors will also gain an appreciation for the wealth and depth of knowledge produced by physicians who practiced in Islamic lands, especially in fields like ophthalmology, pharmacology and surgery. Finally, visitors will understand the lasting and significant impact that medical knowledge produced in the Islamic World has had on modern Western medicine. Through the display of original manuscripts, books, and antique artefacts from the Islamic Studies Library (ISL), and the Osler Library of the History of Medicine, The rise and influence of Medicine in the Islamic World will take visitors on a fascinating journey into the world of Islamic medicine.[3]
Comprising two complementary displays -one at the Islamic Studies Library and other at the Osler Library-, the exhibition will be accessible during libraries opening hours from September 11th to December 22nd, 2023.
[1] For geographical location, contemporary denominations of countries have been used even if the national entities known today did not exist in their current frontiers at the time. The geography of the region was in constant flux during the long period covered by the exhibition and referring to today’s place-names appeared like the easiest way to situate individuals and events.
[2] For dating, both the Gregorian calendar (AD) and the Hijri calendar (AH) have been used most of the times. An exception was made for Greek and European physicians for whom only Gregorian dates are given.
[3]The rise and influence of Medicine in the Islamic World was jointly curated by Anaïs Salamon and Ghazaleh Ghanavizchian from the ISL, and Dr. Mary Hague-Yearl from the Osler Library.
Pre- & early Islamic Medicine
Medical practices before Islam came from Mesopotamian, Egyptian, Persian, Indian, and Greek physicians. After the rise of Islam (7th cent. AD/1st cent. AH), pre-Islamic medicine remained in use until the beginning of the Umayyad Caliphate (660-750 AD/40-132 AH). From the 9th cent. AD/3rd cent. AH onwards, a new type of medicine emerged by adopting Greco-Islamic medical knowledge and recorded as Ḥadīth [Reports from the Prophet Muḥammad]: This Prophetic medicine drawn from Ḥadīth co-existed with other types of medical care – like Greek humoral medicine – and kept developing until the 14th cent. AD/9th cent. AH.
طب النبي لمحمود بن محمد الجغميني . Ṭibb al-Nabī [Prophetic medicine] li-Maḥmūd ibn Muḥammad al-Jighmīnī (13th cent.), 1881. Early Arabic Printed Books from the British Library. Gale database accessed 28 Aug. 2023.
The Translation of Foreign Texts
During the Abbasid Caliphate (750-1258 AD/132-651 AH), significant effort went toward translating medical and scientific works from other cultures and languages. Established in the 9th cent. AD/3rd cent. AH in Baghdad (Iraq), Bayt al-Ḥikmah / بيت الحكمة [The house of wisdom] supported the translation of foreign texts into Arabic. Many Arab physicians started as translators before composing their own works. Two examples are the Arab Nestorian Christian Ḥunayn ibn Isḥāq,[4] the author of a fundamental ophthalmological treatise, and the Syriac Christian Ibn Māsawayh,[5] the author of many works on fevers, leprosy, melancholy, and other topics. The most commonly translated texts at the time were the Compendium on materia medica by Dioscorides[6] as well as the works of Hippocrates[7] and Galen[8] in humoral medicine.
By the end of the 9th cent. AD/3rd cent. AH, Hellenistic humoral medicine – based on the balance between four humors: blood, phlegm, yellow bile, and black bile – had become prominent in the region. However, prophetic medicine was still very popular, and physicians often blended the two approaches together when curing patients until the 14th cent. AD/9th cent. AH.
In the late 9th – early 10th cent. AD/3rd – 4th cent. AH, the first hospitals appeared in Iraq and Egypt and then started spreading throughout the Islamic World. For sovereigns, such institutions were part of charitable endeavors and cam to symbolize political power. For physicians, hospitals were a place where they not only cured patients, but also taught and trained aspiring physicians.
[4]Ḥunayn ibn Isḥāq al-ʿIbādī. حنين بن إسحاق العبادي (Iraq, 808–873 AD/192-259 AH) was the most famous translator of Greek texts into Syriac and Arabic. His translations formed a foundation for the continuation of Galenic medicine amongst Muslim physicians and, through their mediation, in the mediaeval West.
[5]Ibn Māsawayh. ابن ماسويه (Iraq, died 857 AD/243 AH) began his career translating Greek scientific works for the famous Bayt al-ḥikmah, but became a court physician, attending the high society around the caliph.
[6]Dioscorides (Greece, active in the first century C.E.) is Pedanius Dioscorides of Anazarbos, Greek physician and herbalist, and author of De materia medica that formed the basis of the pharmacological tradition of the classical Islamic world.
[7]Hippocrates (Greece, born after 460, died circa 379 B.C.E.) is considered in both the Muslim world and the West as “the father of medicine.” The Corpus Hippocraticum -writings attributed to him- comprises about seventy titles. However, the authorship of many of them has been a matter of dispute since antiquity. Hippocrates nevertheless drew the first outlines of humoral medicine.
[8]Galen (Turkey, 129-circa 216 C.E.) was a Greek-speaking physician born in Pergamum. His vast work (more than 20,000 pages in a standard 1821 edition) deals with all fields of medical science (anatomy, physiology, therapy, pharmacology, surgery), but also extends to philosophy, logic, ethics, etc.
The Organization & Dissemination of Knowledge
In the 10th and 11th cent. AD/4th – 5th cent. AH, compiling and organizing what had become a large body of knowledge became the priority. Thus, comprehensive influential encyclopaedias were composed: examples include/ كتاب المنصوري في الطبKitāb al-Manṣurī fī al-ṭibb [The book on medicine dedicated to al-Mansur] and كتاب الحاوي في الطب / Kitāb al-Ḥāwī fī al-ṭibb [The Comprehensive Book on Medicine] both by Abū Bakr al-Rāzī,[9] and/ كتاب القانون في الطبKitāb al-Qānun fī al-ṭibb [The canon of medicine] by Avicenna.[10] If such encyclopaedic works were not always well received by the medical community at the time of composition, they served as the foundation of later important works like those of Averroes,[11] Ibn al-Nafīs,[12] and many others.
بن سينا لا القانون في الطب. Al-Qānun fī al-ṭibb by Ibn Sīnā, 17th century. Osler Library of the History of Medicine
[9]Abū Bakr al-Rāzī -or Rhazes-. أبو بكر محمد بن زكريا الرازي(Iran, 854-925 or 935 AD/240-313 or 323 AH), known to the Latins as Rhazes, was a physician, philosopher and alchemist. His medical handbook (Mansuri) and other writings were translated over a dozen times into Latin and other European languages.
[10]Ibn Sīnā -or Avicenna-.أبو علي حسين بن عبد الله بن سينا (Iran, 980-1037 AD/370-428 AH) was known primarily as a philosopher and physician, but he contributed to the advancement of many more sciences accessible in his day: astronomy, music, politics, religion, poetry, etc. Divided in five books (1. Generalities, 2. Pharmacology, 3. Special pathology, 4. Treatises, 5. Pharmacopeia), his Qanun is the clear and ordered sum of all the medical knowledge available at the time, augmented from his own observations. The Qanun served as a reference for seven centuries of medical teaching and practice.
[11]Ibn Rushd -or Averroes-. محمد إبن احمد إبن رشد(Spain, 1126-1198 AD/520-594 AH) was known primarily as a philosopher and theologian, but also specialized in the natural sciences (physics, medicine, biology, astronomy). He wrote several treatises about stroke, a neurological disease similar to Parkinson, and the anatomy of the eye. The encyclopaedia co-authored with Avenzoar – or Ibn Zuhr – (Spain, died 1162) entitled Al-Kulliyat fi al-Tibb was translated into Latin in the 14th century A.D. and became a textbook in Europe for centuries (known as the Colliget).
[12]Ibn al-Nafīs. ابن النفيس (Syria, 1210-1288 AD/607-687 AH) is the author of one of the most widely read commentaries on Avicenna’s Qānūn fī l-ṭibb in the pre-modern Islamic world. He was also the first physician to propose that blood travels from the right side of the heart to the left through the lungs (pulmonary transit).
The Emergence of Specialties
Ophthalmology, pharmacology and surgery quickly emerged as medical specialties in the Islamic World as demonstrated by the number of dedicated monographs. Other topics such as anatomy, bloodletting or embryology were also sometimes the subject of monographs, but these did not become as influential as encyclopaedias chapters on the same topics.
Ophthalmology
Ophthalmological works composed as early as in the 9th cent. AD/3rd cent. AH already show very advanced knowledge: grounded in theories inherited from the Hellenic World, they included intricate surgical procedures to treat common eye diseases like cataracts. One of the most renowned works from the early period is تذكرة الكحالين /Tadhkirat al-Kaḥḥālīn [Memorandum of the oculists] by ʿAlī ibn ʿĪsá[13] (11th cent. AD/5th cent. AH). A few centuries later, in the 14th cent. AD/9th cent. AH, Ibn al-Nafīs compiled in a systematic way the ophthalmological knowledge of the time in/ كتاب المهذب في طب العينKitāb al-Muhadhdhab fī ṭibb al-ʿayn [Ophthalmology manual].
جلاء العيون لحكيم شليم فلمنكي / Jalā’ al-‘uyūn [Clarity of the Eyes] by Ḥakīm Shalīm Falamankī, 1863. Osler Library of the History of Medicine
Pharmacology
Physicians in the Islamic Era commonly used the 500 substances described in Dioscorides’ Compendium in addition to drugs used in Indian and Persian medicine. The 10th cent. AD/4th cent. AH writings of Qustā ibn Lūqā[14] included drugs such as camphor or ammoniac that were unknown at the time to Greek and European physicians. In the 12th cent. AD/6th cent. AH, al-Ghafīqī[15] compiled a list of medicinal substances ordered alphabetically entitled كتاب الأدوية المفردة / Kitāb al-adwiyāʾ al-mufradah [The book of simple drugs].
This work served as a basis for a later manual authored by Ibn al-Baytar[16] (13th cent. AD/7th cent. AH) that presented a total of 1,400 medicaments and became a reference for many subsequent guides in the Islamic World and beyond.
/ كتاب الأدوية المفردة للغافقي Kitāb al-adwiyah al-mufradah by al-Ghafīqī, 1256. Osler Library of the History of Medicine
Surgery
Many physicians in the medieval Islamic medical tradition were interested in surgery. One of the most famous surgeons was al-Zahrāwī[17] (11th cent. AD/5th cent. AH) whose thirty-volume encyclopaedia entitled/ كتاب التصريف لمن عجز عن التأليفKitāb al-Taṣrīf li-man ʿajiza ʿan al-taʾlīf [The arrangement of medical knowledge for one who is not able to compile a book himself] was quoted over 200 times by 14th cent. AD/9th cent. AH French surgeon Guy de Chauliac.[18]
Another important contributor to surgical knowledge was Abū al-Faraj ibn al-Quff[19] (13th cent. AD/7th cent. AH) who composed a substantial monograph on surgery, كتاب العمدة في صناعة الجراحة / Kitāb al-ʿUmdah fī ṣināʿat al-jirāḥah [The mainstay in the art of surgery], which comprised twenty chapters covering anatomy, physiology, general surgical principles, and a pharmacopoeia (recipes for compound drugs used in surgery).
التصريف لمن عجز عن التأليف الزهراوي / Al-Taṣrīf liman ‘ajiza ‘an al-ta’līf by al-Zahrāwī, (11th cent.). Bibliothèque Nationale du Royaume du Maroc
[13]ʿAlī ibn ʿIsá al-Kaḥḥāl. علي بن عيسى الكحال (Iraq, died 1038 or 1039 AD/429 or 430 AH) was the best known oculist (kaḥḥāl) of the Arabs. His work, the Tad̲h̲kirat al-Kaḥḥālīn , is the oldest Arabic work on ophthalmology that survived in the original. This comprehensive treatise was translated into Hebrew and Latin in the 15th century A.D.
[14]Qustā ibn Lūqā. قسطا ابن لوقا (Syria, died 912 or 913 AD/299 or 300 AH) worked as a physician and translator -he was fluent in Greek, Syriac and Arabic-. His medical works include treatises on gout, infectious diseases, insomnia, fevers, types of crises in illnesses, the pulse, paralysis-types, causes and treatment, the four “humours”, and phlebotomy.
[15] Al-Ghāfiqi. أبو جعفر أحمد بن محمد الغافقي (Spain, 12th cent. AD/6th cent. AH) was regarded as the best expert on drugs of his time.
[16]Ibn al-Bayṭār. ابن البيطار (Spain, died 1248 AD/646 AH) was a botanist and pharmacologist. Some historians consider he plagiarized al-Ghafiqi’s Kitāb fī l-adwiya al-mufrada to compose his al-Jāmiʿ li-mufradāt al-adwiya wa-al-ag̲h̲d̲h̲iya.
[17]Abū al-Qāsim al-Zahrāwī-or Abulcassis-.أبو القاسم الزهراوي (Spain, 936-1013 AD/ 324-404 AH) was an innovative physician, surgeon and chemist whose influence continued for centuries and extended far beyond the frontiers of the Muslim Worlds.
[18]Guy de Chauliac (France, 1300-1368 AD) was a physician and surgeon famous for his treatise Chirurgia Magna that was translated in numerous languages and served as a reference until the 16th century.
[19]Abū al-Faraj ibn al-Quff. أبو الفرج بن يعقوب بن إسحاق ابن القف (Jordan, 1233-1286 AD/630-685 AH) was a Christian physician and surgeon better known as a writer and educator than as a doctor.
Knowledge Exchanges
The medical community in the Islamic World remained quite productive through the 14th cent. AD/9th cent. AH, especially in Syria and Egypt. In the latter half of the 16th cent. AD/10th cent. AH, early modern European medical ideas, techniques, and drug therapies started filtering into the Islamic World. Dāʾūd al-Antakī[20] included 1,712 mineral, animal and plant substances from Egypt, Europe, India, China, the Levant, North Africa, and Asia Minor. In hisتذكرة أولي الألباب والجامع للعجب العجاب / Tadhkirat ulī al-albāb wa al-jāmiʿ li al-ʿajab al-ʿujāb [Memorandum book for those who have understanding and collection of wondrous marvels] (1568 AD/975 AH), followed the European practice of using China Root (Chub-chini) to cure syphilis. In a treatise dedicated to syphilis written in 1569 AD/ 977 AH, ʿImād al-Dīn Masʿūd Shīrāzī[21] also prescribed China Root as a cure.
In the 17th cent. AD/11th cent. AH, Ibn Sallūm’s[22] treatise entitled غاية الاتقان في تبدير بدان الانسان/ Ghāyat al-itqān fī tadbīr badān al-insān [The culmination of perfection in the treatment of the human body] originally composed in Arabic and later translated into Ottoman Turkish, included translations of several Latin writings by Paracelsus.[23] But knowledge also circulated in the other direction: Europeans became interested in learning of the medical practices then current in the Islamic World. In 1681 AD/1092 AH, Joseph Labrosse[24] published Pharmacopoea Persica ex idiomate Persica in Latinum conversa which consisted of the Latin translation of a Persian book on compound remedies with personal notes and comments.
Fasciculus medicinae by Johannes de Ketham. 1513. Osler Library of the History of Medicine
[20]Daʾūd al-Antakī. داؤود الأنطاكي (Egypt, 16th cent. AD/10th cent. AH) was a blind physician and pharmacist who authored a three-part medical encyclopedia that included descriptions of over 3,000 medicinal and aromatic plants.
[21]ʿImād al-Dīn Masʿūd Shīrāzī.عماد الدین مسعود شیرازی (Iran, mid-16th cent. AD/ mid. 10th cent. AH) was a physician who composed a number of treatises in Persian and Arabic on the therapeutic values of Opium and China root (species of smilax). European influence is visible in his works.
[22] Ṣāliḥ b. Naṣrullāh Ibn Sallūm al-Ḥalabī. صالح بن نصر الله بن سلوم الحلبي (Syria, died 1670 AD/1081 AH) was the head physician of the Ottoman Empire whose writings are often seen as instrumental in the introduction of European Renaissance medicine to the Middle East.
[23]Paracelsus (Switzerland, 1493-1541 AD) was a physician, alchemist, theologian, and philosopher. He is one of the first scientists to introduce chemistry to medicine advocating for the use of inorganic salts, minerals, and metals for medicinal purposes. Instead of the four humour of Hellenistic medicine, he believed there were three humours: salt, sulphur, and mercury respectively representing stability, combustibility, and liquidity.
[24]Joseph Labrosse (France, 1636-1697 AD), also known as Father Angelus of St. Joseph, was a French Carmelite missionary and writer. He played a role in transmitting Persian medical terminology to Europe, and was the first European to make a serious study of Iranian medicine. He also compiled a Persian dictionary with translations into Latin, French, and Italian.
The Rise of European Medicine as the Reference
In the middle of the 18th cent. AD/12th cent. AH, traditional Islamic medicine seemed unable to combat the plague epidemic in Istanbul. The Ottoman sultan Mustafa III ordered a Turkish translation of two treatises by Hermann Boerhaave.[25] These translations, soughing to reconcile and harmonize Boerhaave’s ideas with traditional Islamic medicine, were completed in 1768 AD/1182 AH.
The 19th cent. AD/13th cent. AH witnessed profound changes in the teaching of medicine in the Islamic World as European medical expertise became the reference point. In 1825 AD/ 1240 AH, the Egyptian army hired French physician Antoine-Barthélémy Clot[26] as surgeon-in-chief. A few years later, Clot established a medical school near Cairo which French, Italian and German professors. Similarly, a military medical school, دار الفنون / Dār al-Funūn [The house of arts] founded in Tehran (Iran) in 1850 AD/ 1266 AH offered instruction in French based on European medical texts translated into Persian.
Nevertheless, aspects of medieval Islamic traditional medicine continued to coexist alongside modern European medicine. In the late 19th cent. AD/13th cent. AH, treatises of Ibn Sīnā and Ibn al-Bayṭār, among others, were still printed at the بلاق / Būlaq Press ( / المطبعة الأميريةal-maṭbaʿah al-amīrīyah) in Cairo because they continued to represent a vital tradition.
[25]Hermann Boerhaave (Netherlands, 1668-1738 AD) was a Dutch botanist, chemist and physician considered to be the founder of clinical teaching and of the modern academic hospital, and sometimes referred to as “the father of physiology”. He is best known for demonstrating the relation of symptoms to lesions.
[26]Antoine-Barthelemy Clot (France, 1793-1868 AD) also known as Clot Bey is a French physician and medicine professor who spent most of his life working in Egypt.
Bibliography
Abel-Halim, R. E. (2018). Surgery. In Pormann, P. E. (Ed.), 1001 Cures: Contributions in Medicine & Healthcare from Muslim Civilisation. London: Foundation for Science, Technology and Civilisation. https://www.1001cures.net
Arnaldez, R. (2012). “Ibn Rus̲h̲d”, in: Encyclopaedia of Islam, Second Edition, edited by P. Bearman, Th. Bianquis, C.E. Bosworth, E. van Donzel, W.P. Heinrichs. http://dx.doi.org/10.1163/1573-3912_islam_COM_0340
Bowen, H. (2012). “ʿAlī b. ʿĪsā”, in: Encyclopaedia of Islam, Second Edition, edited by P. Bearman, Th. Bianquis, C.E. Bosworth, E. van Donzel, W.P. Heinrichs. http://dx.doi.org/10.1163/1573-3912_islam_SIM_0512
Brockelmann, C. and Vernet, J. (2012). “al-Anṭākī”, in: Encyclopaedia of Islam, Second Edition, edited by: P. Bearman, Th. Bianquis, C.E. Bosworth, E. van Donzel, W.P. Heinrichs. http://dx.doi.org/10.1163/1573-3912_islam_SIM_0681
Carra de Vaux, B. (2012). “Ṭibb”, in Encyclopaedia of Islam, First Edition (1913-1936), edited by M. Th. Houtsma, T.W. Arnold, R. Basset, et. al. http://dx.doi.org/10.1163/2214-871X_ei1_SIM_5758
Goichon, A.M. (2012). “Ibn Sīnā”, in: Encyclopaedia of Islam, Second Edition, edited by P. Bearman, Th. Bianquis, C.E. Bosworth, E. van Donzel, W.P. Heinrichs. http://dx.doi.org/10.1163/1573-3912_islam_COM_0342
Goodman, L.E. (2012). “al-Rāzī”, in: Encyclopaedia of Islam, Second Edition, edited by P. Bearman, Th. Bianquis, C.E. Bosworth, E. van Donzel, W.P. Heinrichs. http://dx.doi.org/10.1163/1573-3912_islam_SIM_6267
Hamarneh, S. K. (2012). “Ibn al-Ḳuff”, in: Encyclopaedia of Islam, Second Edition, edited by P. Bearman, Th. Bianquis, C.E. Bosworth, E. van Donzel, W.P. Heinrichs. http://dx.doi.org/10.1163/1573-3912_islam_SIM_8659
Hill, D.R. (2012). “Ḳuṣtā b. Lūḳā”, in: Encyclopaedia of Islam, Second Edition, edited by P. Bearman, Th. Bianquis, C.E. Bosworth, E. van Donzel, W.P. Heinrichs. http://dx.doi.org/10.1163/1573-3912_islam_SIM_4567
Meyerhof, M. and Schacht, J. (2012). “Ibn al-Nafīs”, in: Encyclopaedia of Islam, Second Edition, edited by: P. Bearman, Th. Bianquis, C.E. Bosworth, E. van Donzel, W.P. Heinrichs. http://dx.doi.org/10.1163/1573-3912_islam_SIM_3319
Savage-Smith, E. (2012). “al-Zahrāwī”, in: Encyclopaedia of Islam, Second Edition, edited by P. Bearman, Th. Bianquis, C.E. Bosworth, E. van Donzel, W.P. Heinrichs. http://dx.doi.org/10.1163/1573-3912_islam_SIM_8089
Savage-Smith, E., Klein-Franke, F. and Zhu, Ming. (2012) “Ṭibb”, in: Encyclopaedia of Islam, Second Edition, edited by P. Bearman, Th. Bianquis, C.E. Bosworth, E. van Donzel, W.P. Heinrichs http://dx.doi.org/10.1163/1573-3912_islam_COM_1216
Shahpesandy, H., Al-Kubaisy, T., Mohammed-Ali, R., Oladosu, A., Middleton, R., and Saleh, N. (2022) A Concise History of Islamic Medicine: An Introduction to the Origins of Medicine in Islamic Civilization, Its Impact on the Evolution of Global Medicine, and Its Place in the Medical World Today. International Journal of Clinical Medicine, 13, 180-197. https://doi.org.10.4236/ijcm.2022.134015
Shefer, M. (2011). An Ottoman Physician and His Social and Intellectual Milieu: The Case of Salih bin Nasrallah Ibn Sallum1, Studia Islamica, 106(1), 102-123. https://doi.org/10.1163/19585705-12341254
Strohmaier, G. “Ḥunayn b. Isḥāḳ al-ʿIbādī”, in: Encyclopaedia of Islam, Second Edition, edited by P. Bearman, Th. Bianquis, C.E. Bosworth, E. van Donzel, W.P. Heinrichs. http://dx.doi.org/10.1163/1573-3912_islam_COM_0300
Vadet, J.-C. (2012). “Ibn Māsawayh”, in: Encyclopaedia of Islam, Second Edition, edited by P. Bearman, Th. Bianquis, C.E. Bosworth, E. van Donzel, W.P. Heinrichs. http://dx.doi.org/10.1163/1573-3912_islam_SIM_3289
Vernet, J. (2012). “Ibn al-Bayṭār”, in: Encyclopaedia of Islam, Second Edition, edited by P. Bearman, Th. Bianquis, C.E. Bosworth, E. van Donzel, W.P. Heinrichs. http://dx.doi.org/10.1163/1573-3912_islam_SIM_3115
Launched in 2002, the Nakba Archive is an oral history collective based in Lebanon aiming to document the social and cultural lives in Palestine before 1948. Over the years, the Archive interviewed over 650 first generation Palestinian refugees in Lebanon, and recorded “their recollections of life in Palestine and the events that led to their displacement.” The primary objective of the Nakba Archive has been to complete existing written record by allowing refugees to document their histories in their own terms.
“Diana Allan founded the Nakba Archive in June 2002. She has a doctorate in anthropology and film from Harvard University and has worked on a several activist media projects in the region. Video documentaries include: Chatila, Beirut (2002); Still Life (2007); and Terrace of the Sea (2010).” She is currently an Associate Professor in Anthropology & Institute for the Study of International Development (ISID) at McGill University. Co-founder and manager, Mahmoud Zeidan, is a Palestinian refugee from Ayn al-Helweh camp in Lebanon and active member of the Lebanese Center for Refugees Rights Aidun.
Despite not having been updated in a very long time, the Nakba Archive website remains a valuable source of information on where to find, and how to access the interviews conducted in its early years. A few excerpts have been made accessible from the NA website, but the vast majority of the audio and video recordings can today be found in the Jafet Library (American University of Beirut):
Another part of the the project, Photo48, included scanning “personal photos and documents (registration papers, land deeds, marriage licenses, birth certificates, etc.) which refugees brought with them from Palestine.” Unfortunately, these materials don’t seems to have been made available online anywhere. Interested people could always reach out to the Nakba Archives founders to inquire about them.
Last, the Nakba Archive produced in 2005 and 2008 two documentaries about archival work that can be ordered from the website, or found in your library: Nakba Archive Excerpts is available at McGill University Library.
The disruptions caused by the COVID-19 pandemic did not stop the emergence of new ideas and projects at the McGill Islamic Studies Library (ISL). One such example is our collaboration with the Arabic Design Archive (ADA) which started in the middle of the pandemic. Originally, the ISL committed to feed the digital archives with scans of book cover from its collections. As time passed, both parties decided to create a joint exhibition titled Archival Alliance: Discovering Arabic Book Covers that was displayed in the Islamic Studies Library from September 15th to December 15th, 2022.
“The Archival Alliance: Discovering Arabic Book Covers exhibition seeks to highlight and broaden the concept of the histories of graphic design beyond Western contributions to present the wealth of design work produced in the Arab World [….], the exhibit [walked] visitors through the history of Arabic books covers design between 1970 and 2000.”
In early 2020, Moe Elhossieny, Egyptian designer, practitioner historian and researcher, started an archiving project that developed later into the digital Arabic Design Archive. ADA is a non-profit initiative aiming to facilitate knowledge production about Arabic design and its historical context by collecting, digitizing, and making available relevant materials; and to create a digital archive serving both for inspirational and scholarly purposes.
To achieve his goal, Elhossieny began to collect Arabic book covers designs from various collections crowdsourcing stored them in their repository, and posted the most interesting ones on the ADA Instagram account. This is where our former colleague, Mrs. Samah Kasha, learned about the project and contacted Moe Elhossieny to offer our contribution by sending a monthly batch of Arabic book covers’ scans from the Islamic studies Library collection. The collaboration started officially in the Winter of 2021.
Between January 2021 and January 2023, the ISL sent the digital copies of 250 book covers to the ADA archive across a wide range of subjects. Book covers were selected based on their date of publication (to comply with copyright requirements) as well as design and style including typography, graphic design, illustration, and calligraphy. The ADA included these images to their repository and posted some of them (when copyright allowed) on their Instagram account: @thearabicdesignarchive. Our materials have been tagged “Collection of @mcgillislamiclibrary.”
Examples of book covers:
While the Arabic Design Archives was growing and diversifying, the ISL relationship with them tightened, and we suggested expanding the collaboration: a jointly curated exhibition seemed like a good way to do so.
Given the restrictions imposed on everyone by the COVID pandemic, The Archival Alliance: Discovering Arabic Book Covers exhibition was developed in a hybrid format including both a physical display and a digital component. The virtual part of the exhibition consisted in a touch table exhibit that offered visitors a unique interactive digital experience. The physical display featured books from the ISL collection, and the digital display gave access to book covers from the ADA archive.
Physical display in the ISL – Photos: Lauren Goldman
Physical display in the ISL – Photos: Lauren Goldman
Physical display in the ISL – Photos: Lauren Goldman
To incorporate the digital aspect of the exhibition, we asked our colleague Gregory Houston, ROAAr (Rare & Special Collections, Osler, Art, and Archives) Digitization Administrator for help. His expertise in developing touch table experience combined with Moe Elhossieny’s expertise in design resulted in a colorful and engaging touch table exhibit, showcasing books covers, animated clips, documentary videos, illustrated pages presenting the narrative of the exhibition, historical photographs, etc.
Touch Table experience – Video capture: Ghazaleh Ghanavizchian – Featuring: Samira Meshkin (Senior Library Clerk at the Islamic Studies Library)Animated book cover clip created by Moe Elhosseini
The topics covered and the materials included in the The Archival Alliance: Discovering Arabic Book Covers exhibition were identified and selected over the course of several meetings. If more than 500 ISL book covers were scanned and sent to the ADA during our two years-long collaboration, only 20 of them were chosen for the physical display. While selecting the book covers, we realized that three artists had played an important role in designing book covers in the 20th century: Hilmi El-Tuni, Mohieddine Ellabbad and Bahgat Osman. With materials gathered for his personal research and the Arabic Design Archives, Moe Elhossieny was able to create documentary-style videos highlighting the work of the three featured artists (video1, 2 and 3). These videos were available for watching on the touch table.
Bahgat Osman
Hilmi El-Tuni
Mohieddine Ellabbad
video 1. Mohieddine Ellabbad- Video credit: Moe Elhossieny
video 2. Bahgat Osman- Video credit: Moe Elhossieny
video 3. Hilmi Al Tuni Evoking Popular Arab Culture by Yasmine Taan | Copy + Paste Syndrome | Nuqat 2015, YouTube, uploaded by: Nuqat, https://www.youtube.com/watch?v=uW72ub0HIvY
Materials on both the touch table and in the display cabinet were assigned to three main subject areas : Religion, Literature, and History. Book cover design can teach us a lot by reflecting design trends and techniques of the period when they were published. To offer a more meaningful experience to visitors, the Islamic Studies Library made additional books accessible for discovery along side those in the physical display.
The graphic design and visual elements for the promotional materials like postcards (images 1 & 2) and poster (image3) were collaboratively developed.
If the plan was to host a launch or closing event in the presence of Moe Elhossieny, travel restrictions to Canada unfortunately did not allow us to do that.
The exhibition concluded on December 15th, 2023 after attracting numerous visitors from McGill and from the larger Montreal community. We received a lot of positive feedback: some visitors were impressed by the wide range of designs, others found the concept original and unique, others enjoyed the touch table experience and its audio-visual materials.
The exhibition was, curated by Anaïs Salamon, Head of the Islamic Studies Library, Moe Elhosseiny, The Arabic Design Archive, Samah Kasha, former Senior Library Clerk at the Islamic Studies Library, and Ghazaleh Ghanavizchian, Senior Library Clerk at the Islamic Studies Library.
We also thank Dr. Charles Fletcher, Head Library Clerk at the Islamic Studies Library, and Lauren Goldman, Communications and Events Administrator in the Office of the Dean of Libraries, for their invaluable support, and many contributions to this project.
Image 2: Post card-Back side
Image 1: Post card-front side
Image 3: Exhibition posterPhysical display, touch table and additional book covers in ISL- Photo: Ghazaleh Ghanavizchian
This blog post is written by Ghazaleh Ghanavizchian and proofread by Anaïs Salamon.